ローカル環境 (WSL on Ubuntu) に構築した Mongo DB でベクトル検索をしたい
皆さん、こんにちは。LP開発グループのn-ozawanです。
dockerの不要なImageやVolumeを削除したところ、これまで構築したMongoDBが消えてしまいました。MongoDBは裏ではDockerコンテナで動作していますので、削除する際はお気を付けください。
本題です。
MongoDBにはベクトル検索の機能が提供されています。ベクトル検索するにはクラウドのような特別な環境が必要のように感じられるかもしれませんが、ローカル環境でも動きを試すことはできます。今回はローカル環境(WSL on Ubuntu)に構築したMongo DBでベクトル検索を試す手順をまとめました。
目次
Mongo DB でベクトル検索
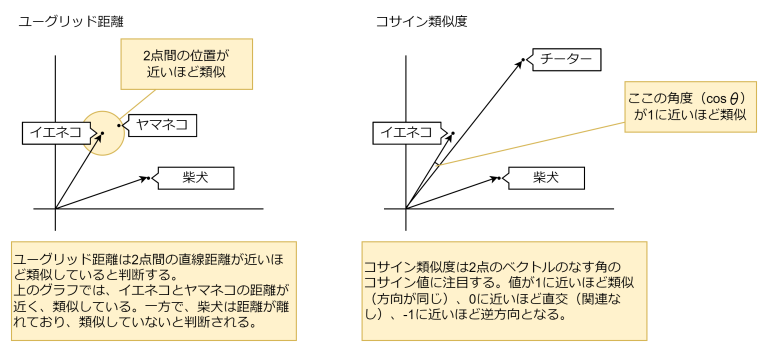
ベクトル検索とは?
ベクトル検索は、データの中から特定の特徴や内容に最も近いものを効率的に見つけ出すための手法です。従来のデータベースが文字列や数値などの「完全一致」や「部分一致」で検索するのに対し、ベクトル検索は「意味の近さ」や「類似度」で検索できるのが特徴です。
Ollamaのインストール
Ollamaは大規模言語モデル(LLM)をローカル環境にて簡単に実行・管理できるオープンソースのプラットフォームです。
Mongo DB はベクトル検索をサポートしていますが、ベクトルDB※ではありません。そのため、文章や画像などのコンテンツ、検索するキーワードを別途ベクトル化する必要があります。Ollamaはベクトル変換するために利用します。
※v8.2以降のプレビュー版では自動的にベクトル化する機能があるようですが、今回は触れません。
Ollamaのインストールは以下の通りです。
sudo apt update && sudo apt install zstd // zstd のインストール
curl -fsSL https://ollama.com/install.sh | sh // Ollama のインストール
ollama pull nomic-embed-text // ベクトル変換を可能とするモデル(nomic-embed-text)を追加データの挿入
Mongo DB にデータを挿入します。mongoshから操作します。
// vector_demo 内のコレクション全てを削除(一旦クリーンな状態にします)
use vector_demo
db.getCollectionNames().forEach(name => db.getCollection(name).drop())
// データを挿入(この時点ではベクトル情報はありません)
db.items.insertMany([
{ title: "red apple" },
{ title: "green apple" },
{ title: "apple juice" },
{ title: "blue ocean" },
{ title: "deep sea" }
])ベクトルに変換
文章をベクトル変換するには、コンソールから以下のコマンドを実行します。
echo "red apple" | ollama run nomic-embed-textmongoshから上記コマンドを実行したいところですが、mongoshからコマンドを実行することができませんので、別途、Node.jsから上記コマンドを実行して、ベクトル情報をMongo DBのドキュメントへ反映するプログラムを作成します。
まずはnpmでプログラムを実行する環境を作成します。
mkdir ollama-embed
cd ollama-embed
npm -y init
npm install mongodbファイルembed.mjsを作成します。内容は以下の通りです。
import { MongoClient } from "mongodb";
import { spawnSync} from "child_process";
const uri = "mongodb://localhost/?directConnection=true";
const client = new MongoClient(uri);
// 文章をベクトルに変換する
function getEmbedding(text) {
const res = spawnSync("ollama", ["run", "nomic-embed-text"], {
input: String(text),
encoding: "utf-8",
timeout: 30_000,
maxBuffer: 10 * 1024 * 1024,
});
if (res.error) throw res.error;
if (res.status !== 0) throw new Error(res.stderr || "ollama failed");
return JSON.parse(res.stdout);
}
// 変換したベクトルを各ドキュメントに追加する
async function run() {
await client.connect();
const col = client.db("vector_demo").collection("items");
const cursor = col.find({});
for await (const doc of cursor) {
const embedding = getEmbedding(doc.title);
await col.updateOne(
{ _id: doc._id },
{ $set: { embedding } }
);
console.log(`embedded: ${doc.title}`);
}
await client.close();
}
run();先ほどのプログラムを実行します。
node embed.mjs成功すると以下が出力されます。
embedded: red apple
embedded: green apple
embedded: apple juice
embedded: blue ocean
embedded: deep seaベクトル検索用インデックスの作成
ここまでで、itemsコレクションの各ドキュメントにembeddingフィールドが追加され、内容は以下のようになっているはずです。
use vector_demo
db.items.find()
[
{
_id: ObjectId('6997bbf9b630dc76638de666'),
title: 'red apple',
embedding: [
0.025105005, 0.08147168, -0.13502309, 0.028353626,
// ... 764 more items
]
}
, { /* ... more documents ... */ }
]embeddingフィールドには768次元のベクトル情報が格納されています。768次元はちょっとイメージが湧きませんね。ベクトル検索をするためには、embeddingフィールドに対して、ベクトル検索のためのインデックスを作成する必要があります。
db.items.createSearchIndex(
"vector_index",
"vectorSearch",
{
"fields": [
{
"type": "vector", // ベクトル検索を有効化
"path": "embedding", // ベクトル検索の対象となるフィールド名
"numDimensions": 768, // 次元数
"similarity": "cosine" // 距離計算の種類 (この場合はコサイン類似度を選択)
}
]
}
)これで準備が整いました。
ベクトル検索の実行
検索キーワードをベクトルに変換します。検索キーワードは「フルーツ(fruits)」で、変換されたベクトル情報はファイルquery.jsonに保存します。
echo "fruits" | ollama run nomic-embed-text > query.jsonmongoshから検索します。
use vector_demo
// ファイル`query.json`の内容を読み込み
const query = JSON.parse(
require("fs").readFileSync("query.json")
);
// 検索実行
db.items.aggregate([
{
$vectorSearch: {
index: "vector_index", // ベクトル検索用インデックスを指定
path: "embedding", // ベクトル検索の対象となるフィールド名
queryVector: query, // "fruits"のベクトル情報
numCandidates: 100, // 候補ベクトルの最大数 (limitの10~20倍程度を指定)
limit: 5 // 最大5件出力
}
},
{
$project: {
_id: 0,
title: 1,
score: { $meta: "vectorSearchScore" }
}
}
])以下が得られます。
[
{ title: 'green apple', score: 0.8258388042449951 },
{ title: 'apple juice', score: 0.8067097663879395 },
{ title: 'red apple', score: 0.8048827648162842 },
{ title: 'blue ocean', score: 0.7115285396575928 },
{ title: 'deep sea', score: 0.6661980152130127 }
]「フルーツ(fruits)」と検索し、「青りんご(green apple)」「赤りんご(red apple)」「リンゴジュース(apple juice)」のそれぞれ80%を超えており、「明確な関連性がある」と判断されました。一方で、「青い海(blue ocean)」は71%で「弱い関連性」、「深海(deep sea)」は66%で「無関係」と判断されました。
このサンプルでは全てのドキュメントが表示されていますが、例えば、scoreを80%以上のドキュメントのみを採用することにより、より関連性の高い項目のみを検索することができるようになります。
おわりに
ベクトル検索は、主に生成AIにおけるRAG(検索拡張生成)で使われる手法です。ベクトル検索が行えることにより、生成AIへの活用が見込めるようになります。
ではまた。








