C言語でHashMapを実装する
皆さん、こんにちは。LP開発グループのn-ozawanです。
先週、遅めの夏季休暇を頂いて大阪万博に行きました。世界中の文化や芸術などを直に触れることができて、とても刺激的で楽しかったです。
本題です。
C言語でKeyValue型のデータストアが欲しいと思ったことはありませんか?JavaScriptやPythonでは言語レベルで用意してくれていますが、残念ながらC言語にはありません。今回はC言語でJava言語のようなHashMapを実装したいと思います。
目次
C言語でHashMap
ゴール
C言語でHashMapを実装します。HashMapはキーと値を設定(put)し、キーを指定することで値を取得(get)することができます。今回はサンプル程度なので、設定(put)と取得(get)のみを実装します。
HashMapの仕組み
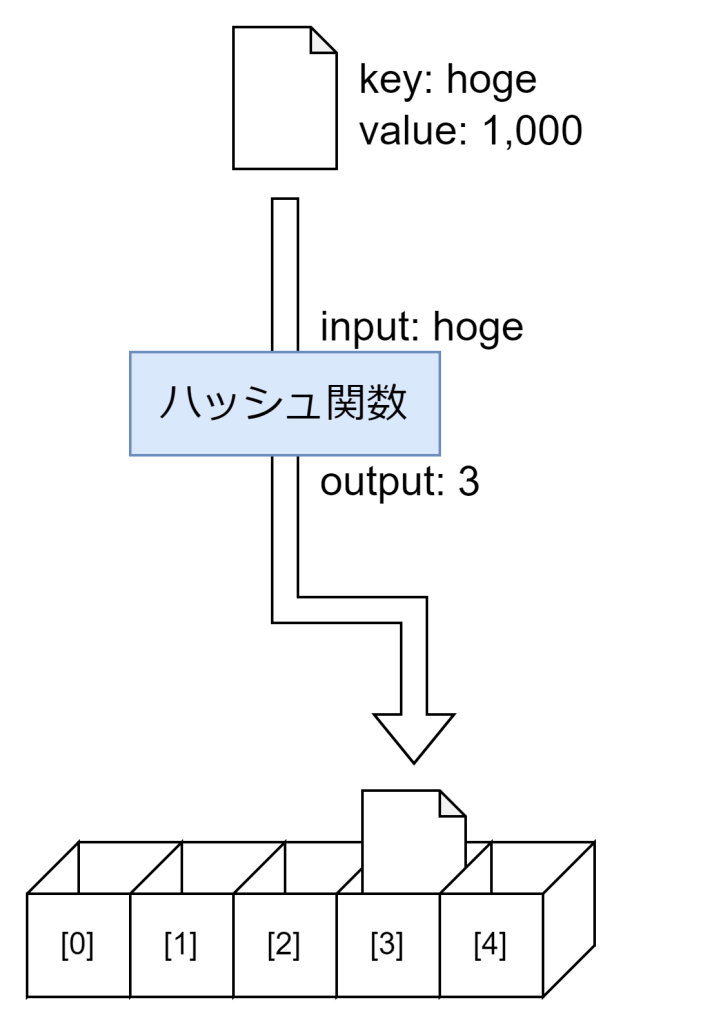
HashMapとは、ハッシュ探索の仕組みを利用したKeyValue型のデータストアです。Java言語であればArrayListに続いて非常にお世話になるクラスです。HashMapは内部に配列を保持しており、キーをハッシュ関数に通して格納先のIndexを求め、格納先のIndexにデータを格納します。
もし、格納先のIndexに、既に他のデータが格納済みの場合、ツリー構造もしくは配列などを用いて、同一Indexに複数のデータが格納できるようにします。
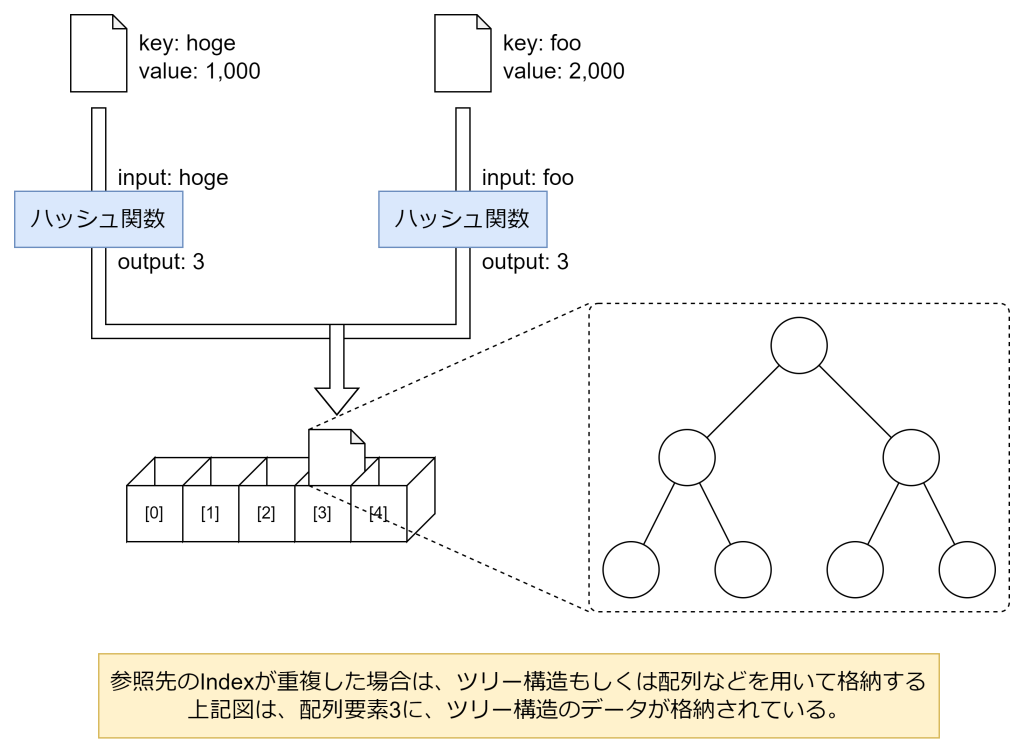
今回は、重複した場合には以前投稿したArrayListを利用します。
Mapインターフェース
まずはMapインターフェースを実装します。「インターフェイス?オブジェクト指向言語じゃないのに何言ってんだ?」と思った方は、過去に投稿した、C言語でオブジェクト指向プログラミング(1回目、2回目)を参照ください。
// メンバ変数
typedef struct _Map {
void (*Map_put)(struct _Map* map, const char* key, void* value);
const void* (*Map_get)(const struct _Map* map, const char* key);
} Map;
// メソッド
void Map_put(Map* map, const char* key, void* value) {
if (map && map->Map_put) {
map->Map_put(map, key, value);
} else {
printf("Map_put not implemented.\n");
}
}
// Map_getも同じように実装するコンストラクタとデストラクタ
HashMapのコンストラクタとデストラクタを実装します。
typedef struct {
char* key; // 文字列キー
void* value; // 値
} HashMapEntry;
typedef struct {
Map parent; // 継承: Map インターフェース
ArrayList** buckets; // バケット配列 (各要素は HashMapEntry を格納する ArrayList*)
int bucketCount; // バケット数
int size; // 要素数
int sizeOfValue; // 値1件のバイト数
} HashMap;
// コンストラクタ
HashMap* HashMap_new(int initialCapacity, int sizeOfValue) {
HashMap* map = (HashMap*)malloc(sizeof(HashMap));
if (initialCapacity < 8) { initialCapacity = 8; }
map->bucketCount = initialCapacity;
map->buckets = (ArrayList**)calloc(map->bucketCount, sizeof(ArrayList*));
map->size = 0;
map->sizeOfValue = sizeOfValue;
// オーバーライド
map->parent.Map_put = HashMap_put;
map->parent.Map_get = HashMap_get;
return map;
}
// デストラクタ
void HashMap_delete(HashMap* map) {
if (!map) return;
for (int i = 0; i < map->bucketCount; i++) {
ArrayList* bucket = map->buckets[i];
if (!bucket) continue;
for (int j = 0; j < ArrayList_size((List*)bucket); j++) {
HashMapEntry* entry = (HashMapEntry*)ArrayList_get((List*)bucket, j);
free(entry->key);
free(entry->value);
}
ArrayList_delete(bucket);
}
free(map->buckets);
free(map);
}設定(put)
キーと値を設定するメソッドを実装します。
// 負荷係数が 0.75 を超えたらリサイズ
#define HASHMAP_LOAD_FACTOR 0.75
// 設定(put)
void HashMap_put(Map* map, const char* key, void* value) {
HashMap* hashmap = (HashMap*)map;
if (!hashmap || !key) return;
// リサイズ判定
if ((double)hashmap->size / hashmap->bucketCount > HASHMAP_LOAD_FACTOR) {
HashMap_resize(hashmap, hashmap->bucketCount * 2);
}
// ハッシュ値を計算し、設定先のIndexを求める
// ハッシュ値はDJB2にて作成する。詳細は割愛。
unsigned long hash = djb2hash(key);
int index = (int)(hash % hashmap->bucketCount);
// バケットが無い場合は作成する
ArrayList* bucket = hashmap->buckets[index];
if (!bucket) {
bucket = HashMap_createBucket(hashmap->sizeOfValue);
hashmap->buckets[index] = bucket;
}
// バケット内に同じキーが存在するかどうかを確認して、あれば上書き
HashMapEntry* existing = HashMap_findEntry(bucket, key);
if (existing) {
// 既存値を上書き
memcpy(existing->value, value, hashmap->sizeOfValue);
return;
}
// 新規エントリ作成
HashMapEntry entry;
entry.key = (char*)malloc(strlen(key) + 1);
strcpy(entry.key, key);
entry.value = malloc(hashmap->sizeOfValue);
memcpy(entry.value, value, hashmap->sizeOfValue);
ArrayList_add((List*)bucket, &entry); // ArrayList が値コピー
hashmap->size += 1;
}
予め用意したバケット配列の要素数の75%を利用している場合、HashMap_resize()で配列を拡張してキーと値を入れなおします。
static void HashMap_resize(HashMap* map, int newBucketCount) {
ArrayList** oldBuckets = map->buckets;
int oldCount = map->bucketCount;
// 新しいバケット配列を作成
map->buckets = (ArrayList**)calloc(newBucketCount, sizeof(ArrayList*));
map->bucketCount = newBucketCount;
map->size = 0; // 再挿入で再計算
for (int i = 0; i < oldCount; i++) {
ArrayList* bucket = oldBuckets[i];
if (!bucket) continue;
for (int j = 0; j < ArrayList_size((List*)bucket); j++) {
HashMapEntry* entry = (HashMapEntry*)ArrayList_get((List*)bucket, j);
// ハッシュ値を計算し、設定先のIndexを求める
unsigned long hash = djb2hash(entry->key);
int index = (int)(hash % map->bucketCount);
// バケットが無い場合は作成する
ArrayList* newBucket = map->buckets[index];
if (!newBucket) {
newBucket = HashMap_createBucket(map->sizeOfValue);
map->buckets[index] = newBucket;
}
// 直接挿入
ArrayList_add((List*)newBucket, entry);
map->size += 1;
}
ArrayList_delete(bucket);
}
// 古いバケット配列を解放
free(oldBuckets);
}
コード中にあるHashMap_createBucket()とHashMap_findEntry()は以下の通りです。単純にArrayListを作成、探索しているだけです。
static ArrayList* HashMap_createBucket(int sizeOfValue) {
ArrayList* list = ArrayList_new(sizeof(HashMapEntry));
return list;
}
static HashMapEntry* HashMap_findEntry(ArrayList* bucket, const char* key) {
if (!bucket) return NULL;
for (int i = 0; i < ArrayList_size((List*)bucket); i++) {
HashMapEntry* entry = (HashMapEntry*)ArrayList_get((List*)bucket, i);
if (strcmp(entry->key, key) == 0) return entry;
}
return NULL;
}
取得(get)
キーから値を取得するメソッドを実装します。
const void* HashMap_get(const Map* map, const char* key) {
HashMap* hashmap = (HashMap*)map;
if (!hashmap || !key) return NULL;
// ハッシュ値を計算し、取得先のIndexを求める
unsigned long hash = djb2hash(key);
int index = (int)(hash % hashmap->bucketCount);
// バケットを取得
ArrayList* bucket = hashmap->buckets[index];
if (!bucket) return NULL;
// バケット内を探索してあれば返却、なければNULLを返却
HashMapEntry* entry = HashMap_findEntry(bucket, key);
if (!entry) return NULL;
return entry->value;
}動作確認
では実際に使ってみましょう。
void process(Map* map) {
// 設定
int v1 = 10, v2 = 20, v3 = 30;
Map_put(map, "apple", &v1);
Map_put(map, "banana", &v2);
Map_put(map, "cherry", &v3);
// 上書き
int v2b = 200;
Map_put(map, "banana", &v2b);
// 取得
const int* gv1 = (const int*)Map_get(map, "apple");
const int* gv2 = (const int*)Map_get(map, "banana");
const int* gv3 = (const int*)Map_get(map, "cherry");
const int* gv4 = (const int*)Map_get(map, "missing");
// 結果表示
printf("apple=%d banana=%d cherry=%d missing=%s\n",
gv1?*gv1:-1, gv2?*gv2:-1, gv3?*gv3:-1, gv4 ? "FOUND" : "NULL");
}
int main() {
HashMap* map = HashMap_new(8, sizeof(int));
process((Map*)map);
HashMap_delete(map);
return 0;
}
$ gcc *.c && ./a.out
apple=10 banana=200 cherry=30 missing=NULL
おわりに
本記事のソースコードでは、Indexが重複した場合は線形検索を行って値を取得します。しかし、これでは性能面で良くありません。一般的には赤黒木などのツリー構造にして効率よくデータを探索します。もし、暇な方は修正してみてください。
ではまた。
















