ニューラルネットワーク ~どうやって学習するの?~
皆さん、こんにちは。LP開発グループのn-ozawanです。
19世紀ごろのアメリカでは、鑑賞目的で公園にリスを放ち、その結果リスが大繁殖しました。リスは農作物を荒らし、ケーブルをかみ切り、人を襲うため、今では害獣扱いを受けているそうです。
本題です。
ニューラルネットワークはどのように学習を行うのでしょうか。ニューラルネットワークの学習方法を学ぶと偏微分などが登場し、数学が苦手な人は躓いてしまうのではないでしょうか。今回は初学者向けに、数学が苦手な人でも何となく分かった気になれるように、図にしながら学習の流れを整理してみました。
目次
ニューラルネットワーク
ニューラルネットワークにおける学習とは?
前回、前々回で、単純パーセプトロンと多層パーセプトロンについて、実際に計算してみました。その際、重み(wi)とバイアス項(b)は適当な値で計算しました。しかし実際には、重み(wi)とバイアス項(b)は適当な値ではなく、学習により最適化された値で計算されます。言い換えれば、ニューラルネットワークの学習とは、重み(wi)とバイアス項(b)に最適値を設定することになります。
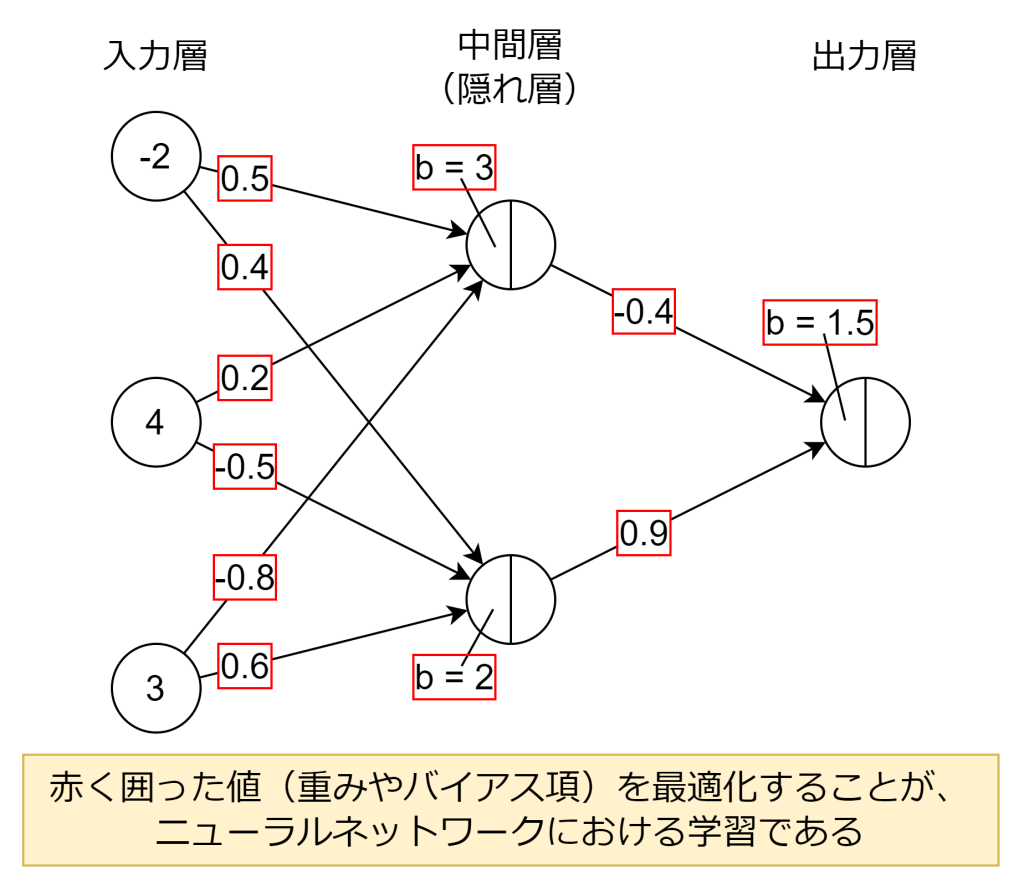
学習の流れ
具体的にどのような流れで学習が行われていくのかを見てみます。
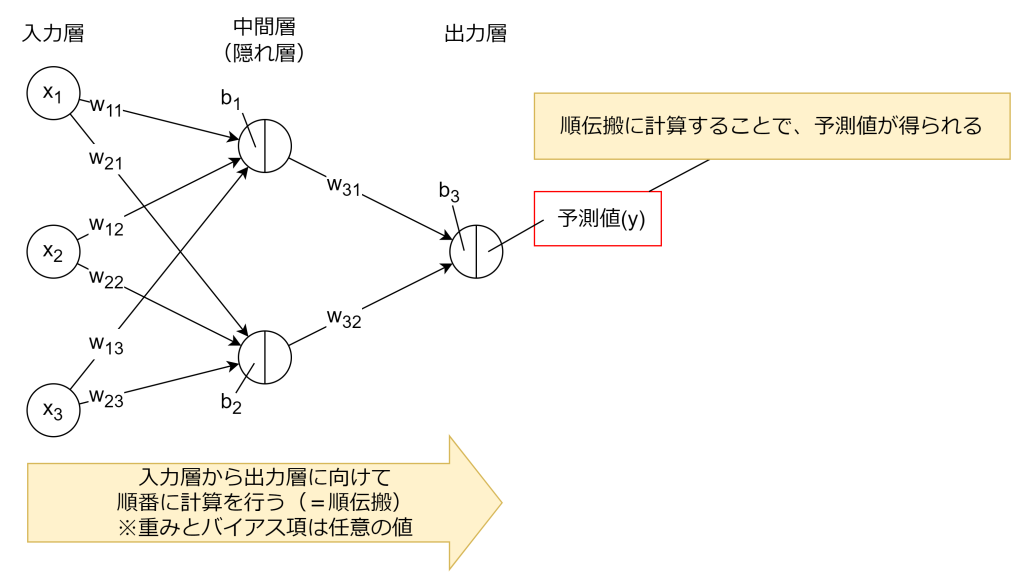
1. 順伝搬
まずは入力層から出力層まで計算を行い予測値を求めます。これは前回、前々回で紹介した計算と同じことをやります。その際、重み(wi)とバイアス項(b)は任意の値で計算します。
2. 損失関数(誤差関数)
損失関数(誤差関数とも言います)により、順伝搬にて算出された予測値から、正解値との誤差を数値化します。この損失関数の数値が大きいほど、予測値と正解値に誤差があることを表します。よって、学習の目的はこの損失関数の数値をできる限り少なくすることになります。
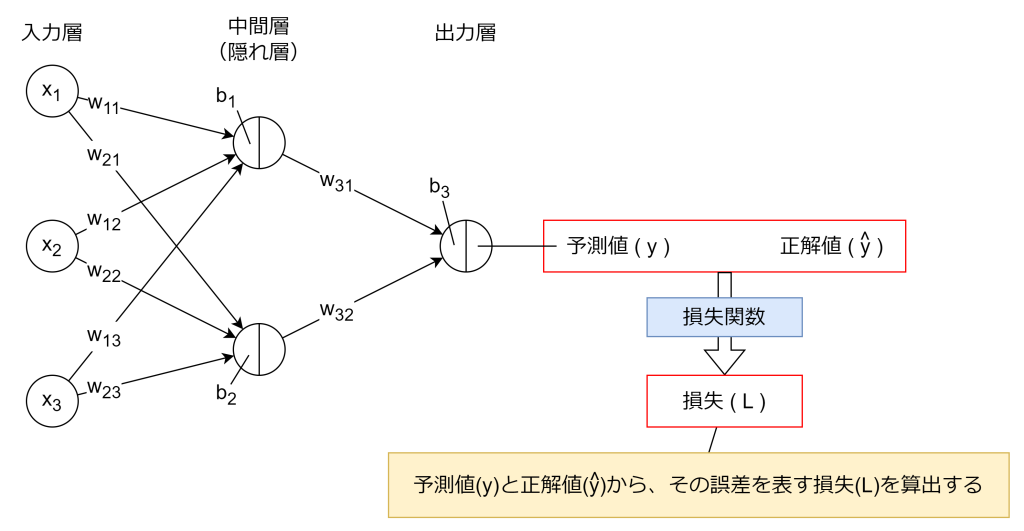
損失関数にはいくつか種類があります。回帰問題であれば「回帰問題の機械学習モデルを性能評価する方法」で紹介した平均二乗誤差(MSE)などがあります。分類問題であれば交差エントロピー誤差が使われます。
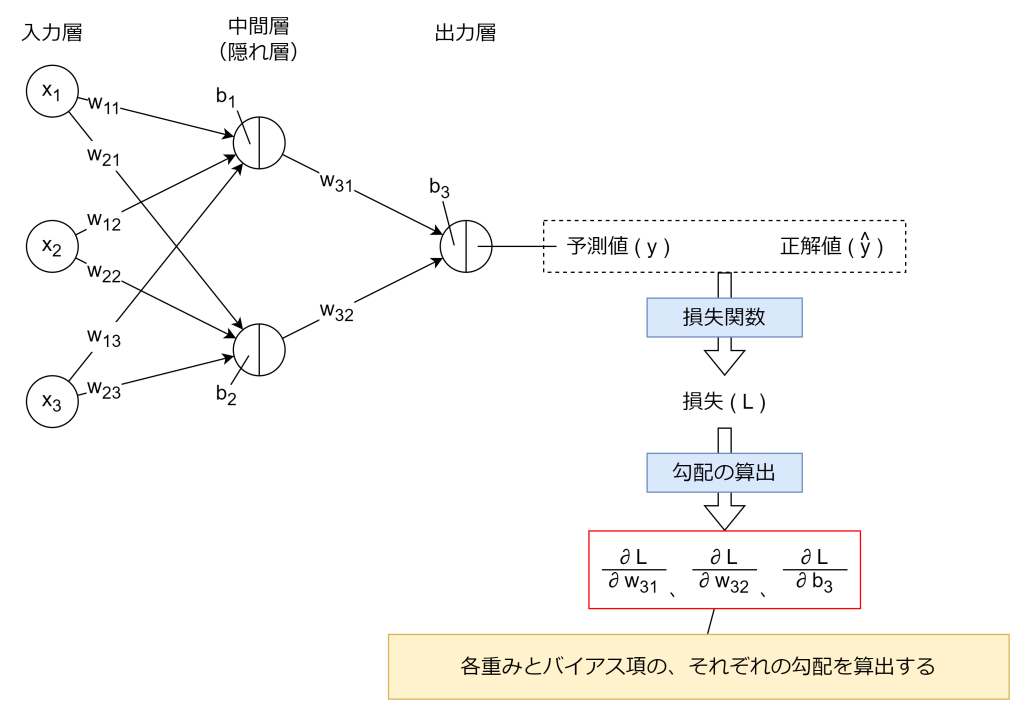
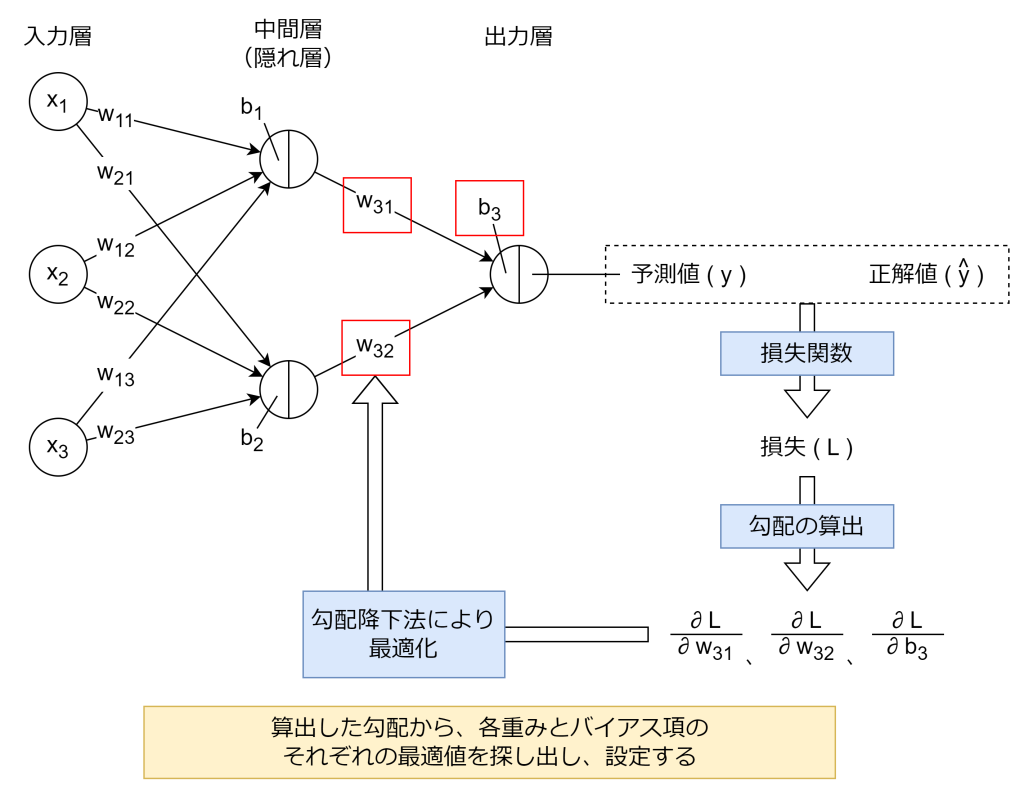
3. 誤差逆伝搬法
誤差逆伝搬法により、各層の重みやバイアス項が損失関数にどれだけ影響を与えているか、損失関数の勾配(偏微分)を求めます。計算された勾配は、後述の勾配降下法などの最適化手法で重み(wi)やバイアス項(b)を更新する際に利用されます。
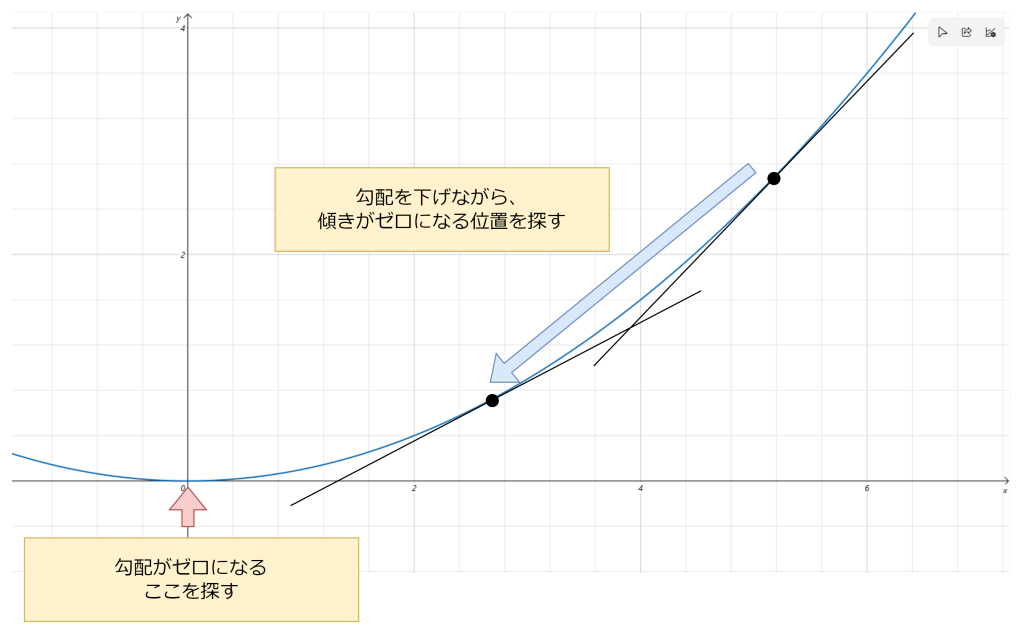
4. 勾配降下法(最適化手法)
勾配降下法は、損失関数の値を最小化するために、重みやバイアス項を少しずつ調整していく最適化手法です。具体的には、誤差逆伝搬法により求めた損失関数の勾配(偏微分)から、その勾配の反対方向に重みとバイアス項を更新します。これにより、損失関数の値が徐々に小さくなっていきます。
勾配降下法は決められた数式で解を求めるものではなく、勾配に沿って降りていくことにより解を探し出す手法です。決められた数式ではなく、手探りで解を探す理由は、多く場合で多次元に渡って計算する必要があるため、簡単には最適解が求まらないとい事情があります。以下は勾配降下法のイメージです。
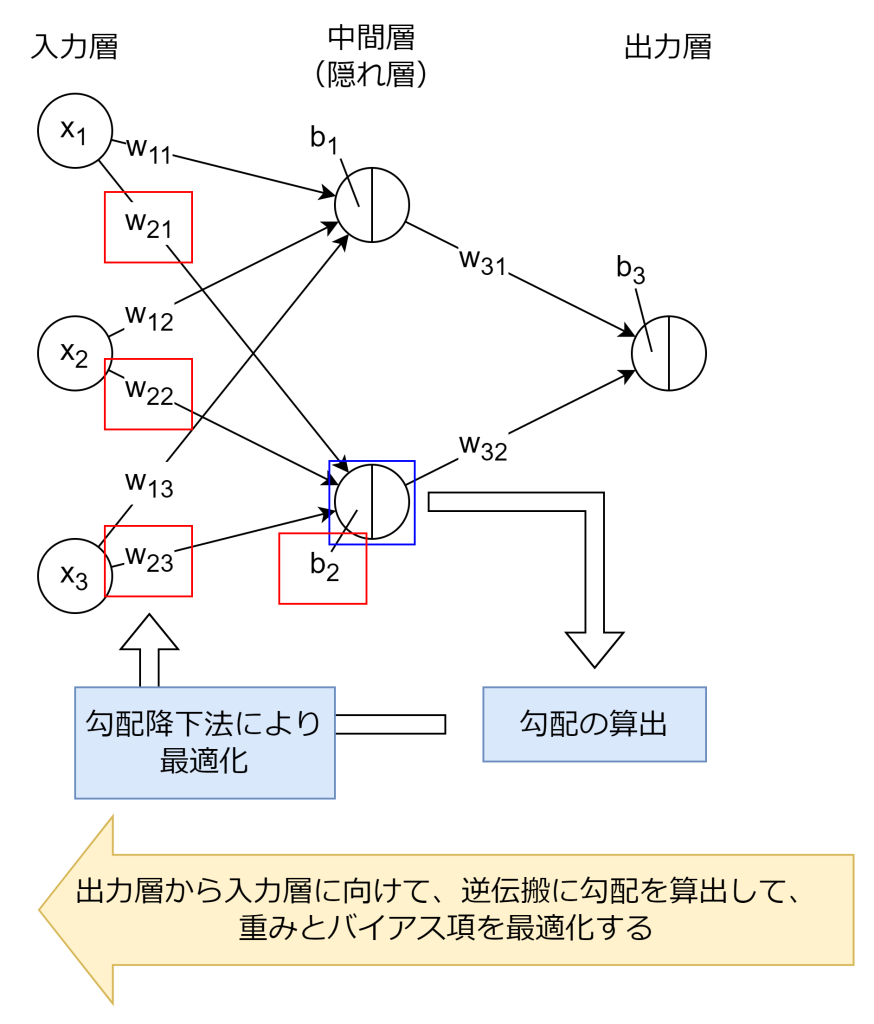
5. 繰り返し
「3. 誤差逆伝搬法」と「4. 勾配降下法(最適化手法)」を出力層から入力層に向けて繰り返し計算します。誤差逆伝搬法という名前は、この出力層から入力層へ逆伝搬するところから命名されています。
おわりに
ニューラルネットワークにおける学習方法を、初学者向けにまとめてみました。全体の流れ、損失関数や誤差逆伝搬法、勾配降下法のそれぞれがどういう役割を持って行われるのかがイメージできたら幸いです。
ではまた。



















