強化学習とは何だろう? ~価値関数と方策勾配~
皆さん、こんにちは。LP開発グループのn-ozawanです。
氷河期は寒冷化により氷床や氷河が存在または拡大する時代のことです。氷河期は比較的寒冷な「氷期」と温暖な「間氷期」を交互に繰り返します。今は260万年前から始まった第四紀氷河時代の間氷期に当たります。温暖化が叫ばれている中、実は今は氷河期だったというのは、なんだか不思議な気分です。
本題です。
強化学習は累積報酬を最大化するために、現在の「状態」から最適な「行動」を選択します。前回はバンディットアルゴリズムを紹介しましたが、今回は価値関数と方策勾配のお話しです。
目次
価値関数と方策勾配
おさらい
前回のおさらいです。強化学習は以下の手順で進め、累積報酬を最大化することを目的とします。
- エージェントが現在の「状態」を観測する
- エージェントが「状態」から「行動」を選択する
- 環境が「報酬」と「次の状態」を返す
- エージェントが報酬をもとに学習する
- 次の状態に移り、1~4を繰り返す
累積報酬を最大化するような行動を選択すれば良いのですが、未知の状態に対してどの行動を取れば良いのか分かりません。そこで「活用」と「探索」をバランス良く行うことで、効率よく強化学習を行います。
その方法の1つとしてバンディットアルゴリズムを紹介しました。バンディットアルゴリズムは「状態」を考慮せず「行動」を選択する方法でしたが、「状態」と「行動」を考慮する方法として「価値関数」と「方策勾配」があります。
価値関数
強化学習は、現在の状態から将来の累積報酬が最大となるような行動を選択する必要があります。価値関数は、状態や行動に価値を設定し、その価値が最大となるように学習する方法です。ここでいう価値とは、将来の累積報酬の期待値になります。価値関数は主に以下の2種類があります。
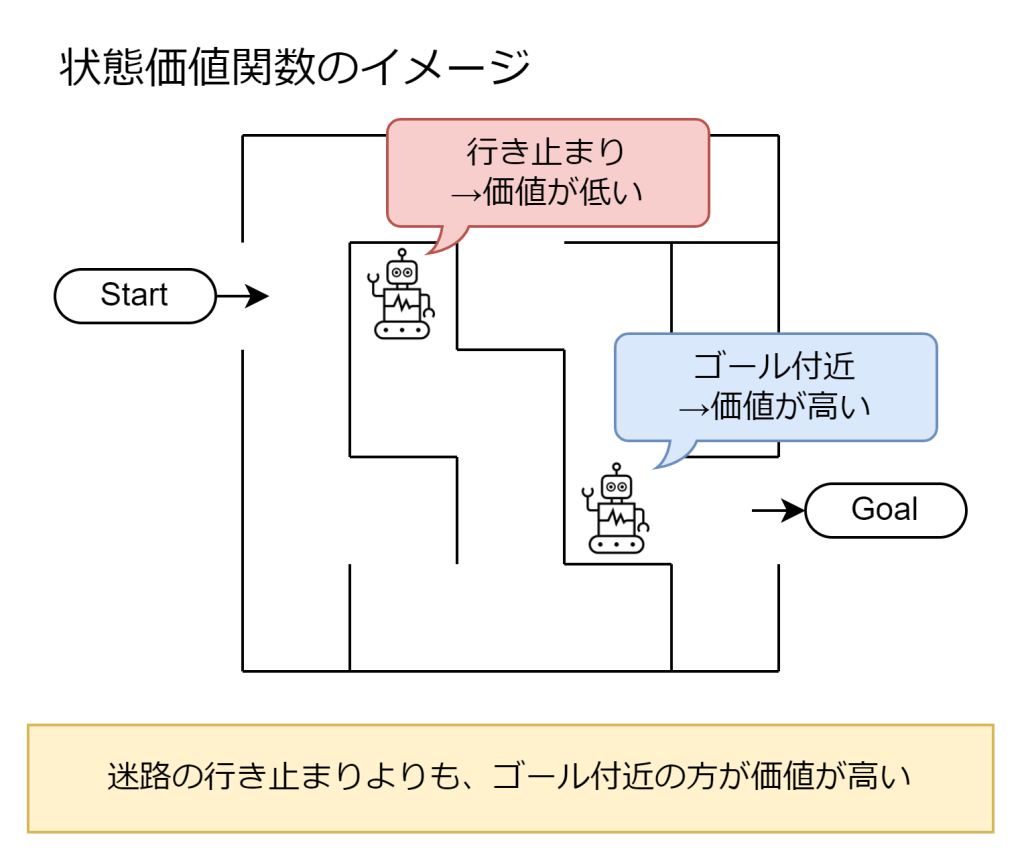
状態価値関数
状態価値関数は、ある状態にエージェントがいるときに、そこから最適な行動を選び続けた場合に将来得られる累積報酬の期待値を表します。
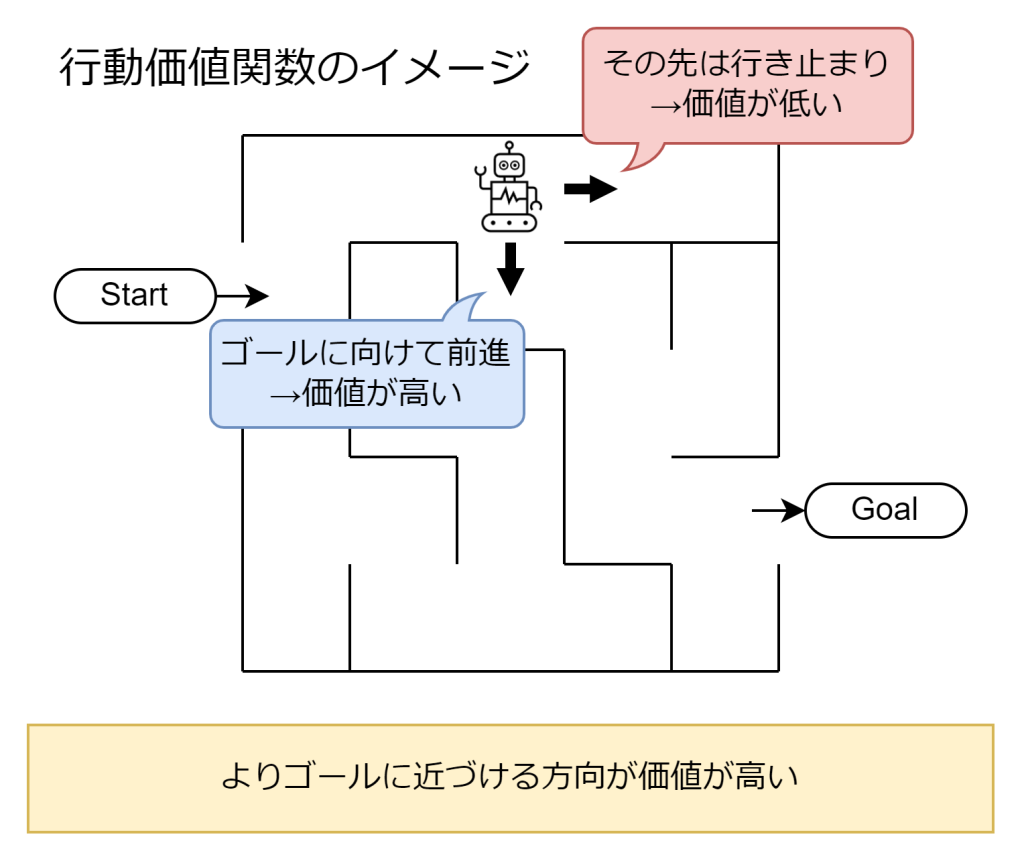
行動価値関数
行動価値関数は、ある状態で特定の行動を選択したときに、その後最適な行動を選び続けた場合に得られる累積報酬の期待値を表します。状態価値関数が「状態」に着目するのに対し、行動価値関数は「状態」と「行動」の組み合わせに着目します。代表的な例としてQ関数(Q値)があり、Q学習などのアルゴリズムで利用されます。
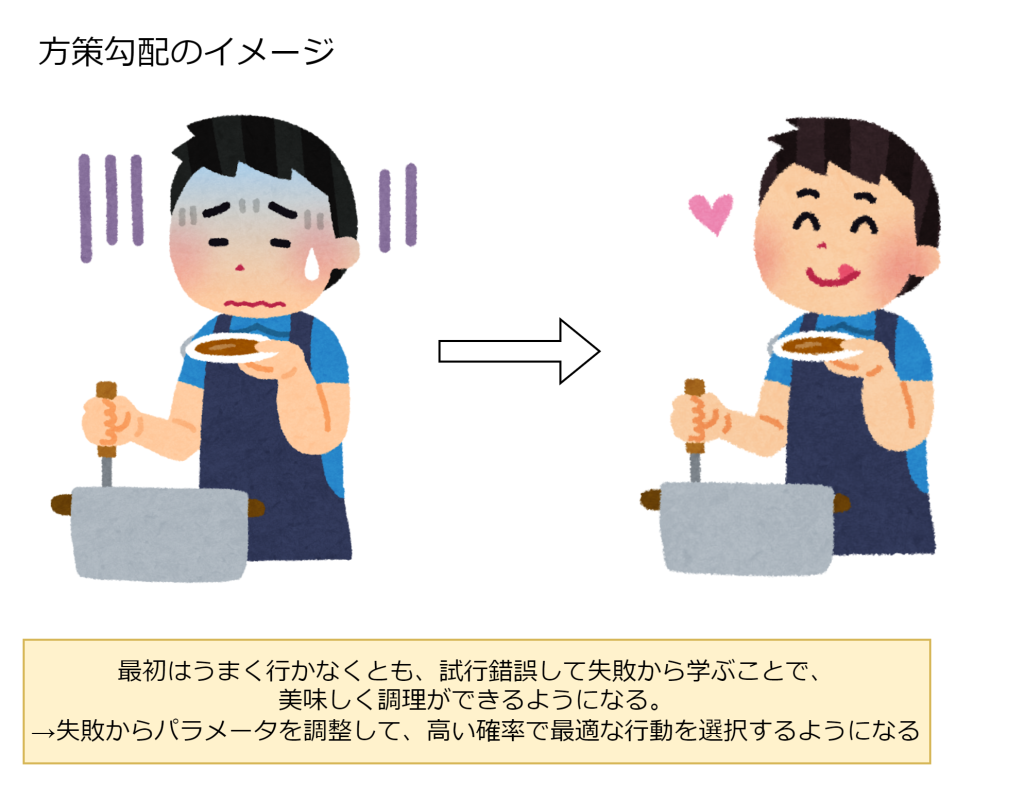
方策勾配
方策とは、ある状態でどの行動を選択するのかを決めるルールです。価値関数は「状態と行動の価値を推定して、その価値をもとに方策を決定する」アプローチでしたが、方策勾配は「方策を直接学習して最適化する」というアプローチになります。
方策勾配法は、「状態」と「行動」から得られた「報酬」をもとにパラメータを調整し、次回以降により良い選択をするための確率を高めていく手法です。方策勾配法はロボット制御など、特に行動の選択肢が大量にあるような場面で使われます。価値関数などでは、行動の選択肢が大量にあると価値の計算量が増え、学習に時間を要してしまうためです。
方策勾配法の代表的なアルゴリズムとして「REINFORCE」や「Actor-Critic」などがあります。これらは、方策のパラメータを累積報酬が大きくなるように調整します。方策勾配の特徴は、連続的な行動空間や確率的な方策にも対応できる点です。
方策勾配法は、価値関数ベースの手法と組み合わせることで、より安定した学習が可能となります(例:Actor-Critic法)。
おわりに
価値関数は累積報酬の期待値を計算します。つまり、未来の累積報酬を推測するのであり、「たぶん、これぐらいの価値があるんだろう」を求めます。なので、価値関数でも一定の確率で「探索」を行います。探索することで計算の精度を高めるのです。方策勾配でも同様に「探索」を行っており、「活用」と「探索」をバランス良く行う、という考え方はバンディットアルゴリズムと同じです。
ではまた。



















