強化学習とは何だろう? ~バンディットアルゴリズム~
皆さん、こんにちは。LP開発グループのn-ozawanです。
7月ですね。七夕の星である織姫星(ベガ)と彦星(アルタイル)の間の距離は15光年になります。お互い15歳若く見えるんですね。
本題です。
機械学習には教師あり学習と教師なし学習の他に強化学習というものがあります。教師あり学習と教師なし学習の違いは学習データのラベルの有無ですが、強化学習はある環境下での報酬を最大化するための学習となります。今回は強化学習とバンディットアルゴリズムについてまとめました。
目次
強化学習
概要
強化学習は、エージェントが環境から状態を受け取り、高い報酬を受け取れるような最適な行動を学習する手法です。強化学習では「状態」「行動」「報酬」のやり取りを1ステップとして、繰り返し進めていきます。具体的には以下の手順で進めます。
- エージェントが現在の「状態」を観測する
- エージェントが「状態」から「行動」を選択する
- 環境が「報酬」と「次の状態」を返す
- エージェントが報酬をもとに学習する
- 次の状態に移り、1~4を繰り返す
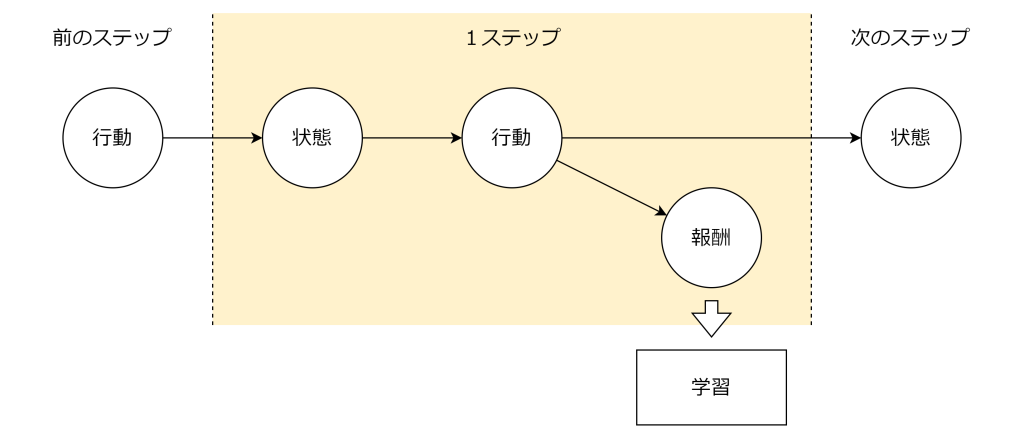
この一連の流れ(状態→行動→報酬→次の状態)は繰り返され、エージェントはどのような状況(状態)でどの行動を取るべきかを試行錯誤しながら学び、将来の累積報酬が最大となる行動を取るようにします。
例えば、ゲームの自動プレイでは、各ターン(時刻)で盤面の状況(状態)を見て手(行動)を選び、勝敗や得点(報酬)を得ることになります。強化学習は、自動車の自動運転やゲームの自動プレイ、ロボット制御、広告配信の最適化など、さまざまな分野で活用されています。
活用と探索
繰り返しになりますが、強化学習は現在の「状態」から、高い「報酬」が得られる「行動」を選択することを学びます。しかし、未知の状態に対して、どの行動により高い報酬を得られるのか分かりません。そのため、強化学習では「活用」と「探索」をバランスよく行うことが重要になります。
活用は、これまでの経験から最も良いと分かっている行動を選択し、確実に報酬を得ることです。
探索は、まだ試したことのない行動を選択し、新しい知識を得ることです。未知の行動を試すことで、より高い報酬を得られる可能性を探ります。
多腕バンディット問題
この活用と探索をシンプルに表現した強化学習の問題に「多腕バンディット問題」があります。
「n本のアーム(腕)を持つスロットマシン」が目の前にあり、各アームを引くと異なる確率で報酬が得られる状況を考えます。どのアームが最も高い報酬をもたらすかは分かりません。プレイヤーは限られた回数の中でアームを選び、できるだけ多くの報酬を得ることを目指します。
この問題のポイントは、「どのアームが良いか分からない」ため、試行錯誤しながら最適なアームを見つける必要があることです。各アームの確率を完璧に把握するために「探索」をしすぎると、報酬を得る前に試行回数の上限に達してしまいます。また、十分な探索もせずに、早々に各アームの確率を決定して「活用」しても、十分な報酬は得られません。

多腕バンディット問題は、強化学習の中でも特に「探索」と「活用」のトレードオフをシンプルに表現した代表的な問題です。
バンディットアルゴリズム
バンディットアルゴリズムは、「活用」と「探索」のバランスを取って、効率的に強化学習を行う手法です。主に「ε-greedy方策」と「UCB方策」の2つがあります。
ε-greedy方策
ε-greedy方策は、確率ε(イプシロン)でランダムに「探索」を選び、確率1-εで、これまでの経験から最も報酬が高いと考えられる「活用」を選びます。
例えば、ε=0.1と設定した場合、10%の確率でランダムなアームを選び、90%の確率で最も期待値の高いアームを選びます。εの値が大きいほど探索を多く行い、小さいほど活用を重視します。ε-greedy方策は実装が簡単で、多腕バンディット問題の基礎的なアプローチとしてよく使われます。
UCB方策
UCB(Upper Confidence Bound)方策は、各アームの「平均報酬」と「試行回数に応じた不確実性」を組み合わせて、次のアームを選択します。
この式の第1項は「活用」(これまでの平均報酬)、第2項は「探索」(試行回数が少ないアームほど値が大きくなる)を表します。UCB方策では、各アームの値が最大となるアームを選択します。これにより、まだ十分に試していないアームも適度に選ばれるため、「活用」と「探索」のバランスを自動的に調整できます。
おわりに
強化学習のアルゴリズムは私たちの身の回りでも良く見かけます。料理店で料理を頼む際、自分の好きな料理を頼むのか(活用)、あえてまだ食べたことのない料理を頼むのか(探索)、悩んだことはありませんか?この時、人間はその時の気分で活用か探索を決めますが、コンピュータはそうはいきません。何かしらのルールで決定するのがバンディットアルゴリズムなのです。
ではまた。



















