分類問題の機械学習モデルを性能評価する方法
皆さん、こんにちは。LP開発グループのn-ozawanです。
指紋は人間の個体ごとに異なるため生体認証で利用されます。同じく牛の鼻紋も個体ごとに異なるため、牛の個体管理として利用されています。
本題です。
その分類問題の機械学習モデルが、どれくらいの精度で分類できるのかを評価することは重要です。なんとなく分類できていそう、というよりは、きちんと数値化できていると安心できます。今回は分類問題における機械学習モデルの性能評価についてお話しします。
目次
モデルの性能評価
概要
分類問題における機械学習モデルの性能評価は、モデルが与えられたデータに対してどれだけ正確に分類できるかを測定するプロセスです。主に分類問題では、混同行列を用いてモデルの予測結果を分析し、正解率、適合率、再現率、F値などの指標を算出します。これらの指標を活用することで、モデルの強みや弱み、バランスの良さを客観的に評価できます。
混同行列
混同行列は、分類モデルの予測結果と実際の正解ラベルを比較して、どのような分類ミスが発生しているかを可視化するための表です。例えば、提示された画像が「ネコ」なのか「ネコ以外」なのかを分類するケースを考えてみます。その場合、以下の4つの結果が得られることになります。
- ネコの画像を、ネコに分類した(TP:真陽性)
- ネコの画像を、ネコ以外に分類した(FN:偽陰性)
- ネコ以外の画像を、ネコに分類した(FP:偽陽性)
- ネコ以外の画像を、ネコ以外に分類した(TN:真陰性)
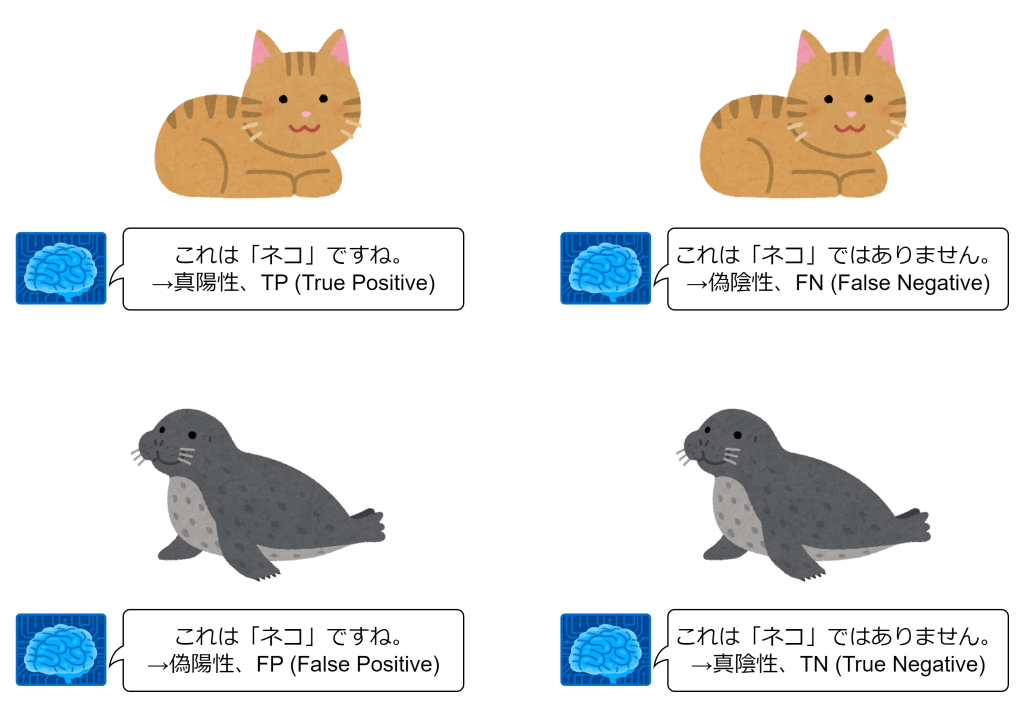
これを表にすると以下のようになります。
| 分類した値 | |||
|---|---|---|---|
| ネコ | ネコ以外 | ||
| 実際の値 | ネコ | 真陽性 TP (True Positive) | 偽陰性 FN (False Negative) |
| ネコ以外 | 偽陽性 FP (False Positive) | 真陰性 TN (True Negative) | |
混同行列を使うことで、単なる正解率だけでなく、どのような誤分類が多いか、モデルがどちらのクラスを苦手としているかなど、より詳細な性能分析が可能になります。
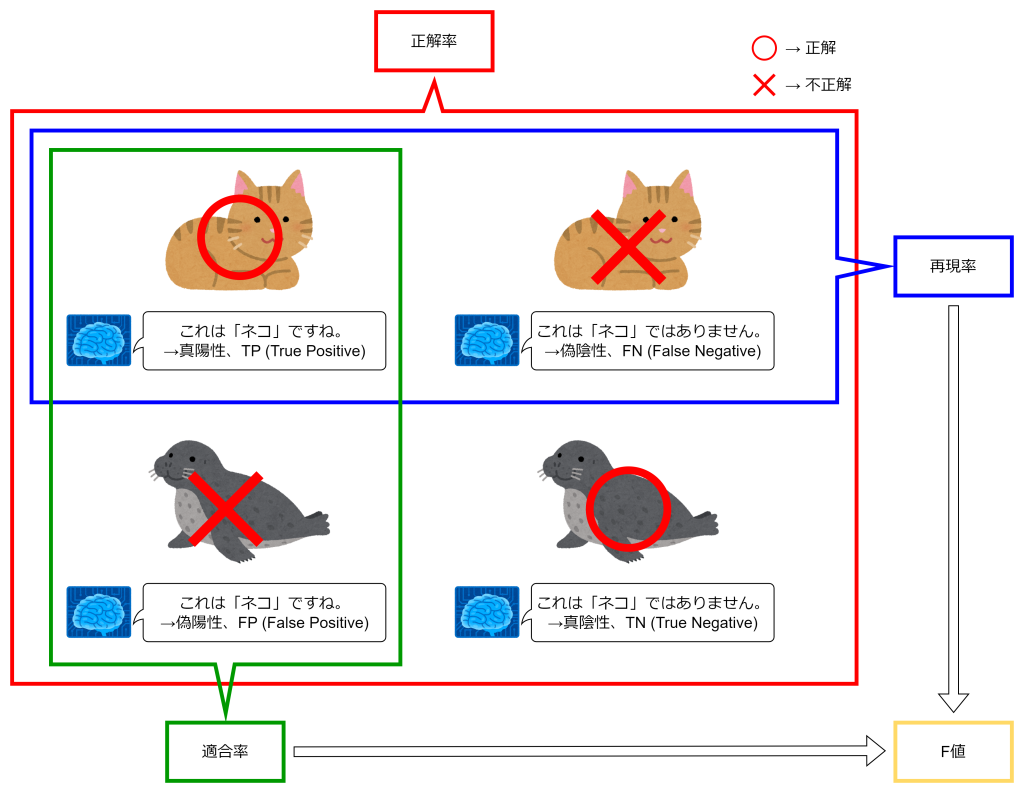
正解率
正解率は、モデルが全体のデータのうち、どれだけ正しく分類できたかを示す指標です。全予測数のうち、正解した割合を計算します。
モデルを評価するには正解率で十分な気がしますが、実は正解率だけではモデルを正しく評価することができません。例えば、ネコの画像を5件、ネコ以外の画像を95件に対して、その全てを「ネコ以外」と分類した場合、その正解率は95%と高くなってしまいます。5件のネコの画像に限定してみると、その正解率は0%であり、それは期待する結果とは遠いものになります。
評価指標には正解率の他に、適合率と再現率、その両方を合わせた指標であるF値が必要になります。
適合率
適合率(Precision)は、モデルが「ネコ」と予測したもののうち、実際に「ネコ」であった割合を示す指標です。誤検出(偽陽性)が少ないほど適合率は高くなります。
再現率
再現率(Recall)は、実際に「ネコ」であるもののうち、モデルが正しく「ネコ」と予測できた割合を示す指標です。見逃し(偽陰性)が少ないほど再現率は高くなります。
F値
F値(F1スコア)は、適合率と再現率の調和平均であり、両者のバランスを評価する指標です。適合率と再現率のどちらか一方だけが高い場合でも、F値は高くなりません。分類モデルの総合的な性能を測る際によく使われます。
おわりに
評価指標は1つではなく、色々な指標でもってモデルを評価します。AIを習い始めたころは沢山出てくるので、覚えるのが大変でしたが、私は以下のような図を頭に思い浮かべて覚えました。
ではまた。



















