交差検証による学習と評価
皆さん、こんにちは。LP開発グループのn-ozawanです。
暑いですね。梅雨はどこに行ったのでしょうか。建物の中にいても熱中症になることがありますので、細目に水分補給をしましょう。
本題です。
機械学習の目的は、手元にあるデータを学習することにより、未知のデータに対して予測することです。この未知のデータに対して正しく予測できているのかを評価する手法として交差検証があります。今回は交差検証についてのお話です。
目次
交差検証
概要
機械学習を行った後には、そのモデルの汎化性能(未知のデータに対してどれぐらい高い予測性能を出せるのか)を評価する必要があります。そのため、機械学習用に収集したデータのすべてを訓練データとして機械学習させてしまうと、そのモデルの評価が正しくできません。よって、機械学習用に収集したデータから、訓練用のデータと検証用のデータに分割して機械学習を行います。これを交差検証と言います。
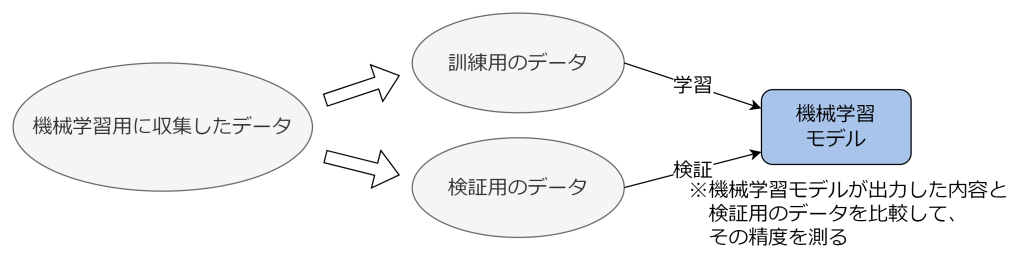
交差検証は言い換えれば、そのモデルが過学習していないかを評価するための手法です。過学習はモデルの汎化性能を低下させます。交差検証を行うことで過学習の兆候を検出し、ハイパーパラメータやモデル構造を調整することにより過学習を抑えることができます。
交差検証にはいくつかの方法があります。本日はホールドアウト検証、k-分割交差検証、リーブワンアウト交差検証の3つを取り上げます。
ホールドアウト検証
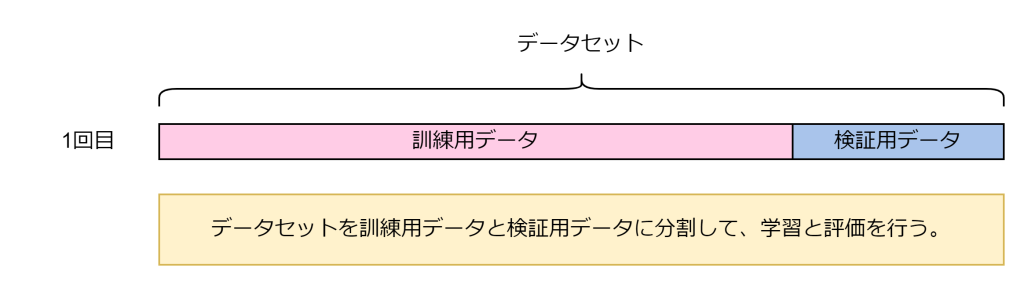
ホールドアウト検証は、データセットを訓練用データと検証用データの2つに分割し、訓練用データでモデルを学習させ、検証用データでその性能を評価する方法です。一般的には、データの7~8割を訓練用、残りを検証用に使います。
分割は無作為に行われるため、その分割内容によってはデータの偏りが発生し、評価結果が不安定になりやすいデメリットがあります。一方で学習・評価の回数が1回で済むため計算コストが低くなります。
k-分割交差検証
k-分割交差検証は、データセットをk個のほぼ等しいサイズのフォールド(分割)に分けて評価する方法です。各フォールドを1回ずつ検証用データとし、残りのk-1個を訓練用データとしてモデルを学習・評価します。これをk回繰り返し、すべてのフォールドで得られた評価結果の平均を最終的なモデル性能とします。
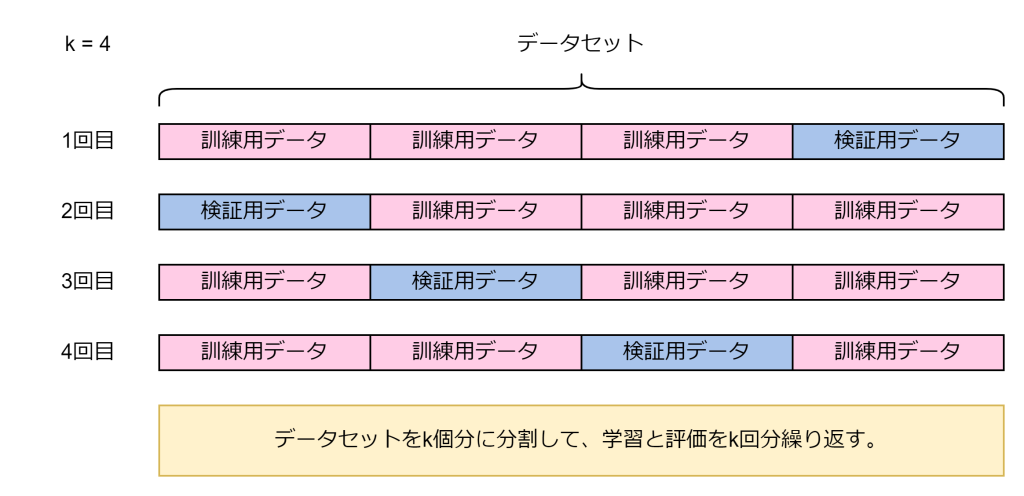
ホールドアウト検証と比べて、全てのデータを効率的に学習・評価することができるため、評価結果が安定しやすくなります。一方でk回分の学習・評価が必要なため、計算コストが高くなります。
リーブワンアウト交差検証
リーブワンアウト交差検証は、データセット内の各データを1つずつ検証用データとし、残りすべてを訓練用データとしてモデルを学習・評価する方法です。これをデータの数だけ繰り返し、すべての評価結果の平均を最終的なモデル性能とします。
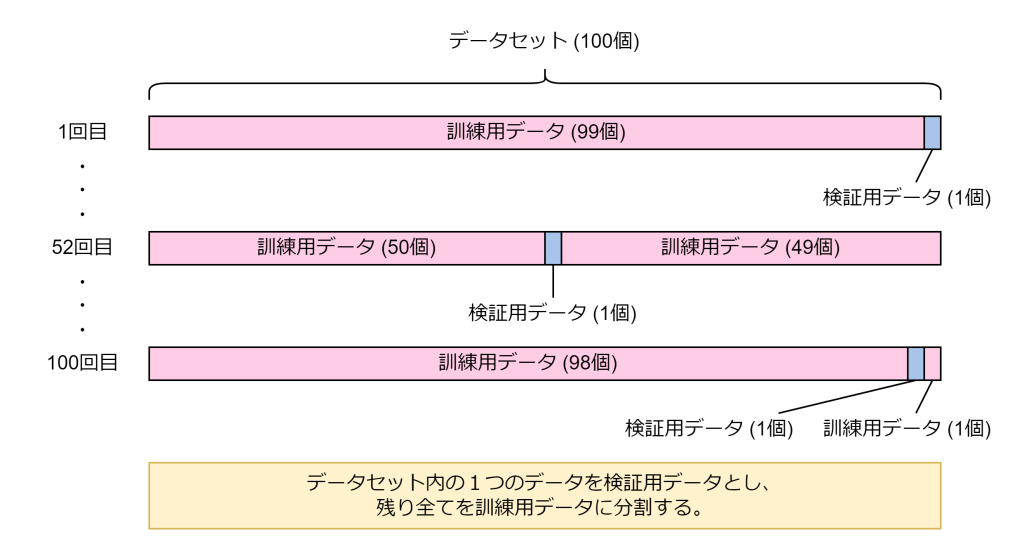
この方法は、データを最大限に活用でき、評価のバラツキが少ないという利点がありますが、データ数が多い場合は学習・評価の回数が増えるため、計算コストが非常に高くなります。特に小規模なデータセットで、より厳密な評価を行いたい場合に利用されます。
おわりに
データセットの数が十分に多い場合は、ホールドアウト検証が有効となります。一方で、データセットの数が少ない場合はリーブワンアウト交差検証により効率的に学習する方が良いでしょう。k-分割交差検証はそのどちらでも有効で、計算コストとのバランスを考慮して、目的に応じて適切なkを選択します。データ量や計算資源、評価の目的に応じて、適切な手法を選択することが重要です。
ではまた。



















