過学習と著作権
皆さん、こんにちは。LP開発グループのn-ozawanです。
今週の金曜日(6/13)にアイオスオープンが開催されます。私は今年も不参加です。
本題です。
機械学習で問題となるのは過学習です。近年、生成AIの利用が広がるにつれて、著作権侵害の懸念も広まっています。今回は過学習と、過学習による著作権侵害についてお話しします。
目次
過学習
過学習とは
過学習とは、機械学習モデルが訓練データに対して過度に適合しすぎてしまい、未知のデータに対する予測性能が悪くなる現象です。人間に例えると、テストの過去問の回答だけを丸暗記して、その問題の本質を一切理解せず、新しい問題が出題されると回答できなくなる現象に近いと思います。この過学習が起こると、訓練データに対する精度は高くなりますが、新しいデータに対しては誤った予測をしやすくなります。
過学習は、モデルが訓練データのノイズや例外的なパターンまで学習してしまうことで発生します。前回の投稿では、知識獲得のボトルネックの一例として、訓練データにノイズや誤情報が含まれることをお話ししました。まさしく、このノイズや誤情報が過学習の原因となります。
訓練データのノイズとは、本来学習すべきパターンとは無関係な、偶発的・例外的なデータや誤ったデータのことを指します。例えば、データ入力時のミス、センサーの誤作動、外れ値、ラベル付けの誤りなどがあります。ノイズは、現場での手動入力や自動計測機器の精度不足、データの取得条件が一定でない場合などに混入しやすくなります。何も対策せずに機械学習を行うと、そういったノイズまで学習してしまい、過学習となり予測精度を低下させます。
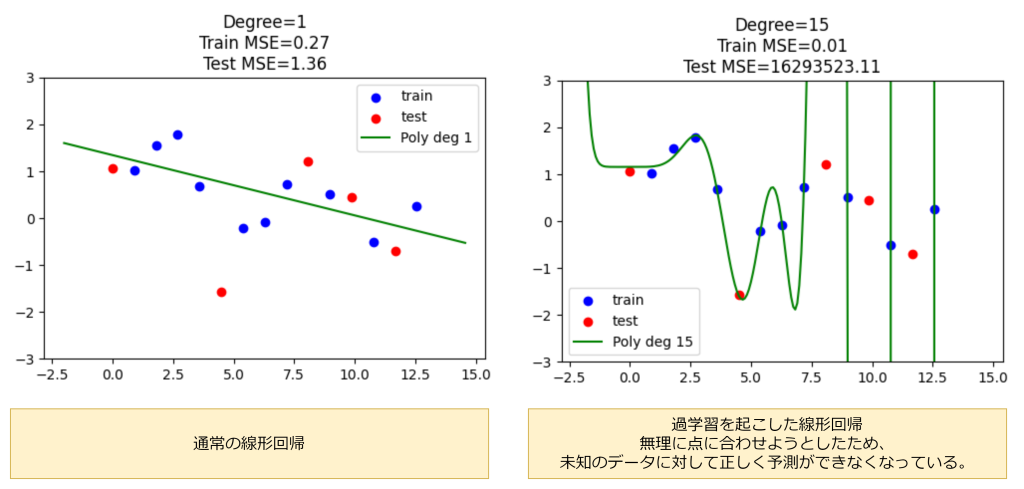
過学習を防ぐためには、訓練データの多様化、データの分割(訓練・検証・テスト)、モデルの複雑さの制御、正則化手法の導入などが有効です。
過学習と著作権
文化庁が実施したセミナー「AIと著作権II」では、以下の記載があります。
著作権法第30条の4では、情報解析等に伴い著作物を利用する場合(※)のような著作物に表現された思想又は感情の享受を目的としない利用行為(非享受目的で行われる利用行為)は、原則として著作権者の許諾なく行うことが可能とされています。
(※)例:AIの学習データとして用いるために著作物を収集(複製)する場合等
文化庁「AIと著作権II」 14P
「享受」を目的とした行為とは、著作物の視聴等を通じて、視聴者等の知的・精神的欲求を満たすという効用を得ることに向けられた行為をいいます。
文化庁「AIと著作権II」 15P
要は、著作物を解析目的で機械学習させるのであれば、著作権の侵害に該当しないことになります。一方で、享受を目的とした行為が認められる場合、著作権の侵害に該当するということになります。では、具体的に「享受を目的とした行為」とは何でしょうか。文化庁の見解は以下の通りです。
学習データである著作物の類似物(創作的表現が共通したもの)を生成させることを目的としたAI学習(※)を行うための、学習データ(著作物)の収集
(※) 例:生成AIの基盤モデルに対する追加学習(ファインチューニング)のうち、意図的に「過学習」させることを目的として行うもの等
文化庁「AIと著作権II」 21P
(※) 生成・利用段階で、学習データである著作物の類似物が生成される事例があったとしても、それだけで直ちに享受目的が併存していると評価されるものではありません。他方で、類似物の生成が著しく頻発するといった事情は、享受目的の存在を推認する上での一要素となります。
過学習した生成AIモデルは、高頻度で過学習したデータを出力します。つまり、特定の著作物を過学習した場合、その著作物に似たコンテンツが生成されるようになるため、「享受を目的とした学習である」と認められるわけです。意図的に過学習させることはもちろんのこと、意図的ではなくても、過学習している事実を認識しつつ放置することも問題となるようです。
このように、過学習は予測精度の低下以外にも、場合によっては法的責任が問われる重大な問題なのです。
おわりに
「享受を目的とした行為」の具体例は、過学習の他にもいくつか示されており、全体を通して非常に興味深かったです。もし興味がある方は、文化庁のページ「AIと著作権について」に資料が公開されていますので、一読することをお勧めします。
ではまた。



















