AI分野の問題 その3
皆さん、こんにちは。LP開発グループのn-ozawanです。
今年は6月時点で台風が1つも発生しておらず、9年ぶりのことだそうです。
本題です。
AIが学習するためには、人間が学習データを与える必要があります。学習データを与えるためには、その学習データの元となる知識を得る必要があります。今回はその知識を得る際の問題である身体性と知識獲得のボトルネックについてお話しします。
目次
AI分野の問題
身体性
「百聞は一見に如かず」ということわざがあります。「百回聞くよりも自分の目で一回見た方が確実」という意味です。旅行でも、事前にさまざまな情報を集めて想像を膨らませても、実際に現地に行くと新しい発見があります。人は「聞く」以外にも、「見る」「嗅ぐ」「触る」など五感を使って情報を得ています。
人間は、身体を持つことで物事を感知し、学習し、思考します。AIもロボットのように身体を持つことで、単なるデータ処理だけでなく、実際の経験を通じて学習し、より豊かな知識や柔軟な適応力を獲得できると考えられています。

現在、生成AIなどの多くのAIは身体を持ちません。そのため、現実世界での直接的な経験や感覚情報を得ることができません。例えば、物の重さや質感、温度などを実際に感じ取ることができず、データとして与えられた情報だけに頼ることになります。これにより、AIは人間のような直感的な理解や柔軟な対応が難しくなり、現実世界での応用範囲が限定されるという課題があります。
知識獲得のボトルネック
AIが知識を獲得する際には、いくつかのボトルネック(制約)が存在します。先ほどの身体性もその内の1つです。以下にボトルネックの代表例をいくつか挙げます。
文脈や背景知識を教えることの難しさ
以前、SNSで日本語の「大丈夫」が難しいというインド人のコメントが話題になりました。風邪や怪我をしていないという意味の「大丈夫」もあれば、断る意味での「大丈夫」もあります。このインド人は「ナンのお代わりはいるか?」という問いに対して「大丈夫です(結構です)」と答えられて、困惑されたとのことです。
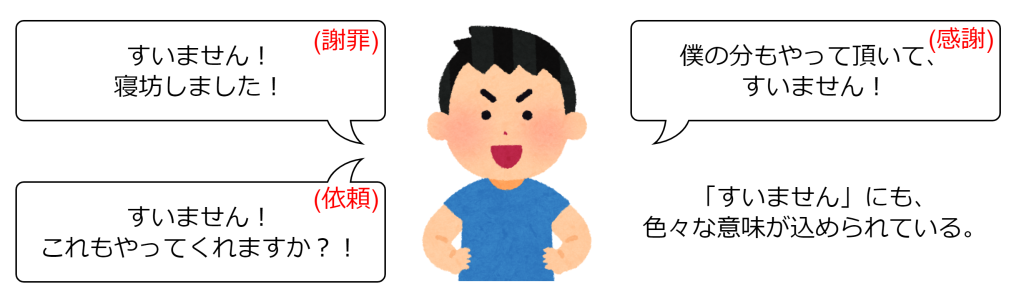
このように、文章の文脈や背景知識がないと、正しく解釈するのが困難なケースがあります。もちろん学習させれば対処可能ではありますが、このような知識すべてをAIに学習させることは現実的に不可能でしょう。
しかし、最近は大規模言語モデルの発達により、こうした課題も徐々に解決しつつあるように感じます。
専門的・希少な知識のデータ化が困難
所謂、「職人」と呼ばれる人たちには、その人にしか知りえない知識や技術があります。その知識や技術をデータ化してAIに学習させようとしても、それらを獲得することは非常に困難です。なぜなら、その知識や技術の多くは、その人の経験から得たものであり、多くが暗黙知となっているためです。そういった暗黙知を正確に言語化して相手に伝えることは非常に難しいことです。

これらの暗黙知をうまくヒアリングして獲得できたとしても、今度は獲得した知識が矛盾していたり、一貫性がなかったりする問題が発生します。なぜなら、その知識はその人にとって感覚的に得られたものであり、体系的にまとめられた知識ではないからです。
ノイズや誤情報を含むデータによる誤った知識の獲得
現在のAIは人間が学習データを用いて学習させていますが、その学習データは必ずしも正確ではなく、ノイズや誤情報が含まれています。教師あり学習で用いる学習データには、データ1つに対してラベルを付与する必要がありますが、データの数が多ければ多いほど、正確なラベルを付与するのが難しくなります。
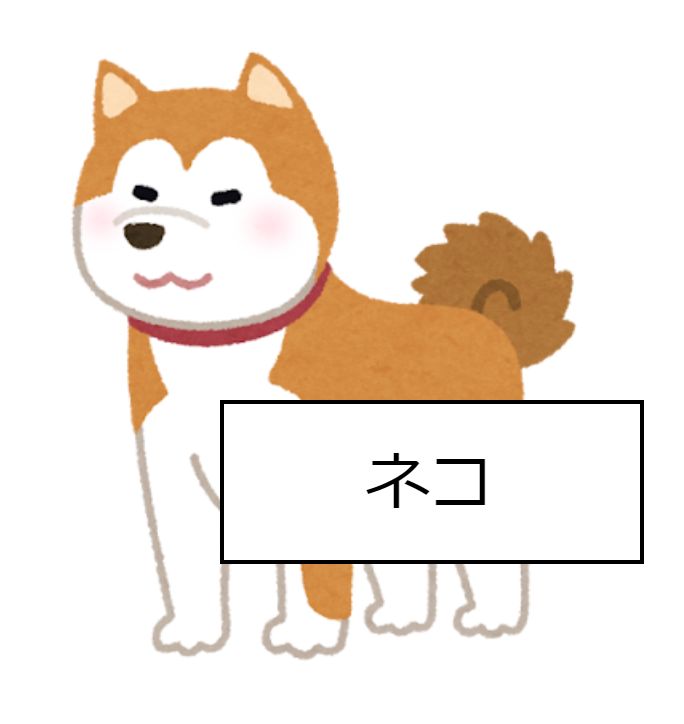
例えば、ImageNetは1,400万を超える画像データセットで、自由に学習データとして用いることができます。1,400万を超える画像すべてに正確なラベルを付与するのは現実的に不可能であり、実際に誤ったラベルが付与されている画像もあります。また、統計学においても、その測定方法によっては想定外の誤差が発生します。こうしたノイズが学習データに混じることは十分にあり得ます。
おわりに
学習データはAIの性能を大きく左右します。また、人が学習データを用意する際はもちろん、AIが自動的に収集する際も、著作権や個人情報などへの配慮が必要となります。学習データを用意する際は、可能な限りコストをかけた方が良いかもしれません。
ではまた。



















