k-means法とは何か?
皆さん、こんにちは。LP開発グループのn-ozawanです。
シマウマの模様は虫よけになります。黒毛和牛をシマウマ模様にしたところ、虫を振り払おうとする行動が7割も減った、という研究結果もあります。
本題です。
データセットを特定の条件でいくつかのグループに分類することで、そのデータの特徴や傾向を分析することができます。教師なし学習の分野ではいくつかのクラスタリング手法が存在しますが、今回はその内の1つであるk-means法についてお話します。
目次
k-means法
概要
k-means法は、クラスタリング手法の一つで、データをk個のクラスタ(グループ)に分類するアルゴリズムです。分類されたクラスタの特徴や傾向は人間が分析します。主に教師なし学習の分野で使用され、データのパターン認識やセグメンテーションに活用されます。
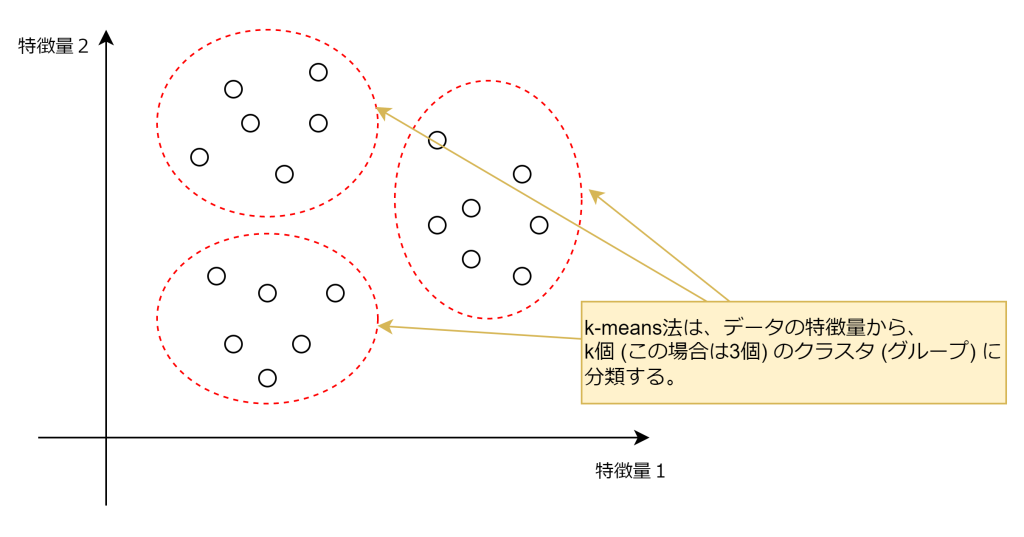
k-means法は、各クラスタの重心を計算し、データポイントを最も近い重心に割り当てることでクラスタを形成します。このプロセスを繰り返し、クラスタ内のデータのばらつきを最小化することを目指します。
アルゴリズムの手順
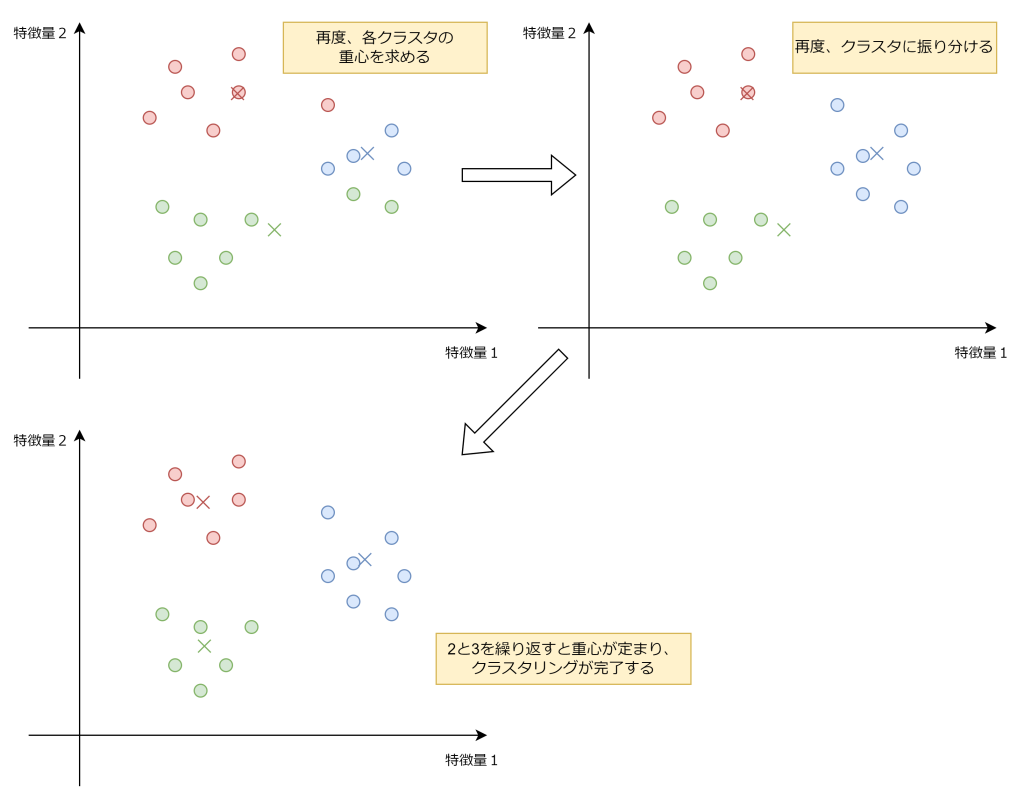
k-means法は以下の手順によりクラスタリングを行います。
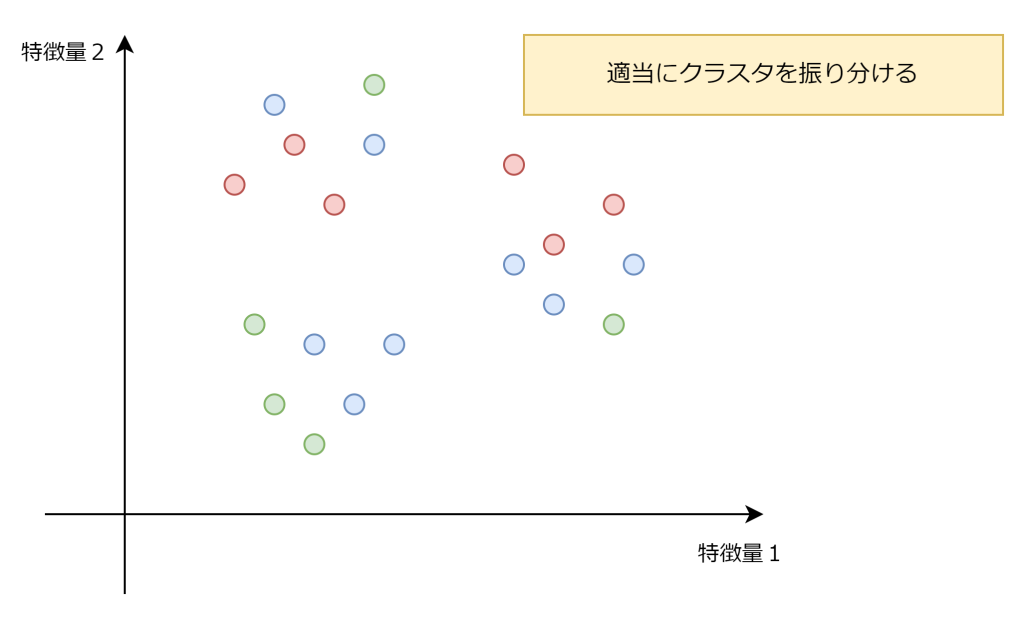
1. データをランダムにクラスタを振り分ける
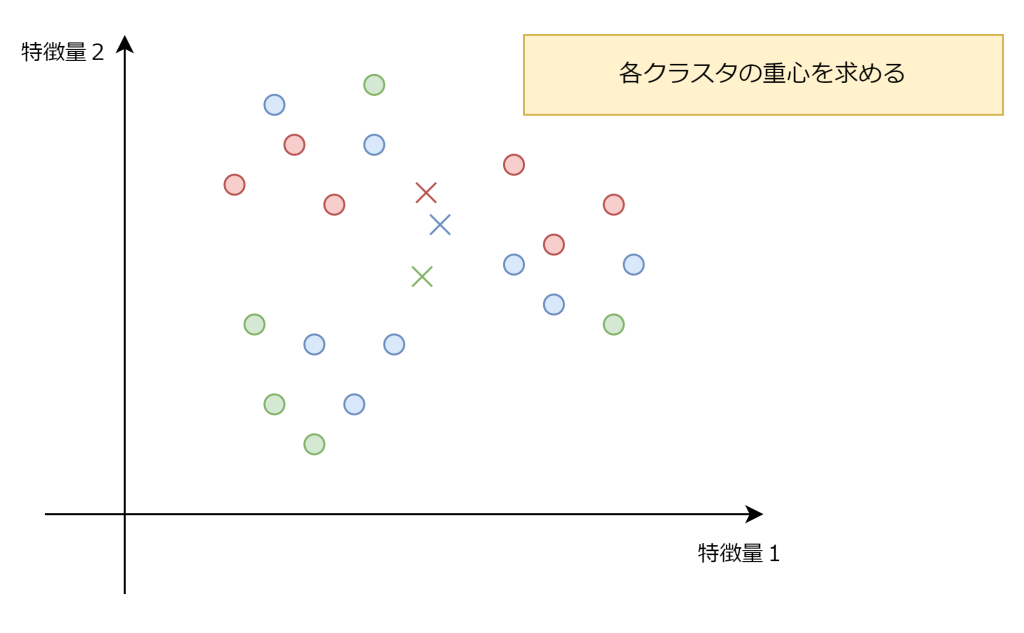
2. 各クラスタの重心を求める
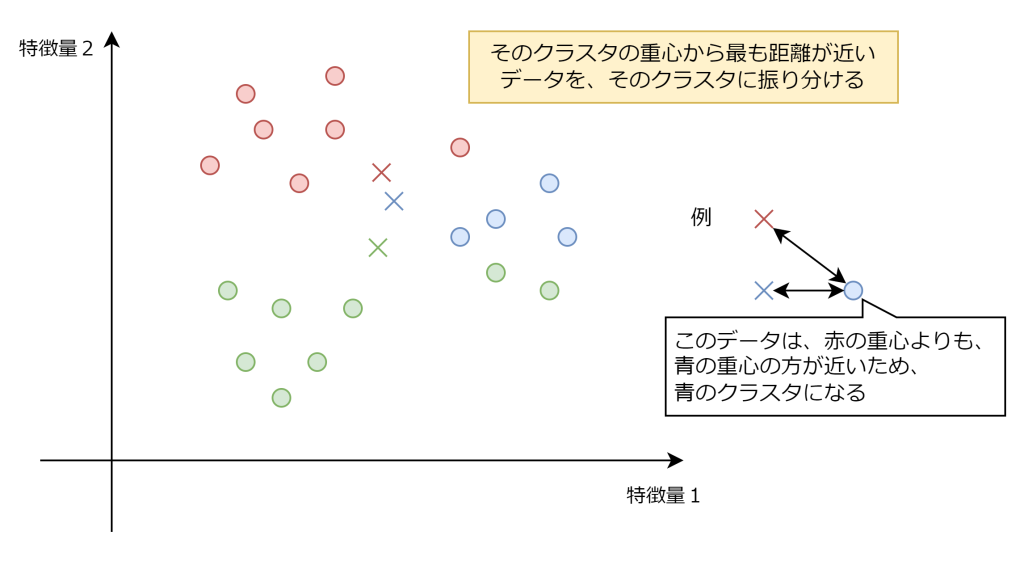
3. 求めた重心から、距離が最も近いデータに対して、再度クラスタに振り分けなおす
4. 重心の位置が変化しなくなるまで、2と3を繰り返す。
実装例
k-meas法をscikit-learnで実装すると以下のようになります。scikit-learnは機械学習を行うpythonのライブラリです。
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# サンプルデータの作成
data, _ = make_blobs(n_samples=150, centers=3, cluster_std=1, random_state=0)
# k-meansクラスタリングの実行
kmeans = KMeans(n_clusters=3, random_state=0)
kmeans.fit(data)
# クラスタリング結果の取得
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
# 結果のプロット
plt.figure(figsize=(8, 6))
for i in range(3):
plt.scatter(data[labels == i, 0], data[labels == i, 1], label=f'Cluster {i+1}')
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', marker='x', s=100, label='Centroids')
plt.legend()
plt.title('K-Means Clustering')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.show()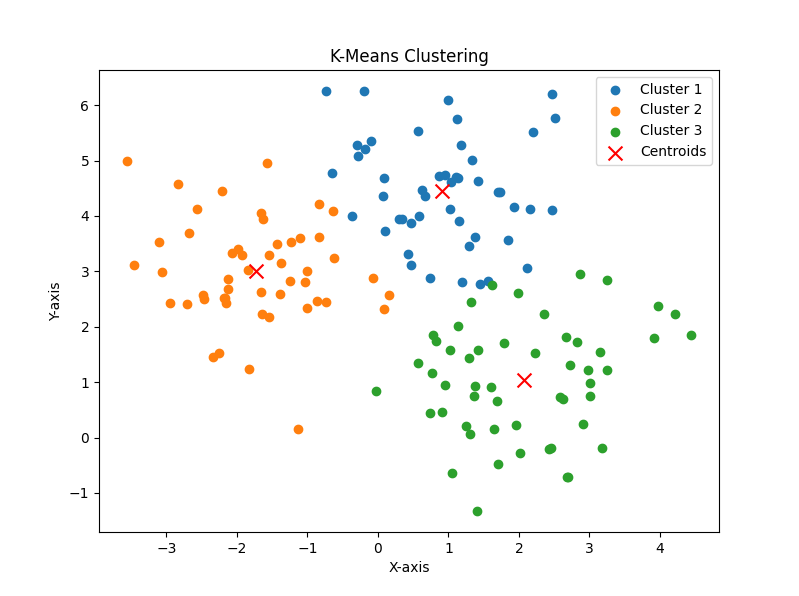
おわりに
k-means法はシンプルで計算コストも低く、大規模データにも適用が可能です。一方で、クラスタが球状であることを想定しているため、複雑な形状のクラスタには不向きなど、得手不得手があります。また、クラスタの数は事前に人間が決める必要があり、クラスタ数によっては精度に影響を与えるため、注意が必要です。
ではまた。



















