サポートベクターマシン (SVM) の基本だけでも知りたい
皆さん、こんにちは。LP開発グループのn-ozawanです。
今年のゴールデンウィークは飛び石連休ではありますが、皆さんは何か予定を入れられていますか?私は先日ソロキャンプに行ってきました。
本題です。
サポートベクターマシンは高次元のデータを効率よく分類することができるアルゴリズムで、ディープラーニングが登場するまでは機械学習で人気のアルゴリズムだったそうです。今回はそんなサポートベクターマシンの基本について整理しました。
目次
サポートベクターマシン (SVM)
概要
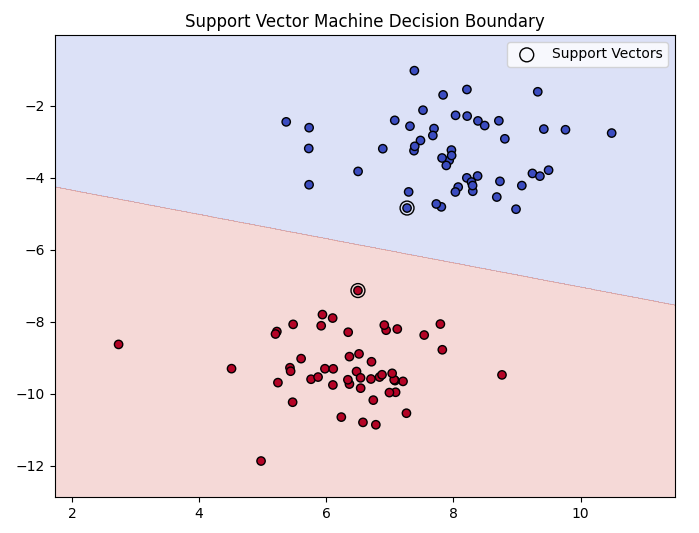
サポートベクターマシン (SVM) は、主に分類に使用される教師あり学習アルゴリズムの一つです。SVM は、データポイントを異なるクラスに分けるための最適な境界線を見つけることを目的としています。このアルゴリズムは、特に高次元データや非線形なデータに対して効果的であり、カーネル関数を使用してデータを高次元空間にマッピングすることで、複雑な分類問題を解決します。
基本的な考え方
サポートベクターマシン (SVM) の基本的な考え方は、データポイントを異なるクラスに分けるための最適な境界線を見つけることにあります。以下の条件を満たす境界線を探します。
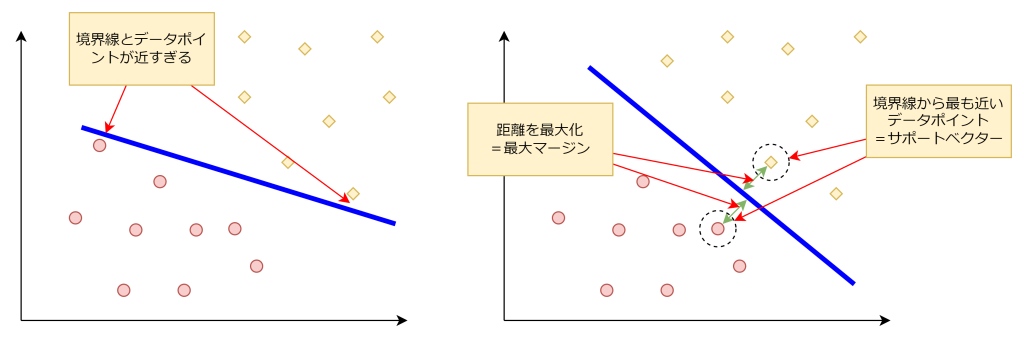
最大マージン
境界線と最も近いデータポイント(サポートベクター)との距離を最大化します。例えば以下の図では、左側の図はデータポイントと境界線が近すぎるため、直感的に適切な境界線ではないことが分かるかと思います。一方で右側の図は、データポイントと境界線が適度な距離で引かれているため、誤判定なく分類されることが期待出来ます。
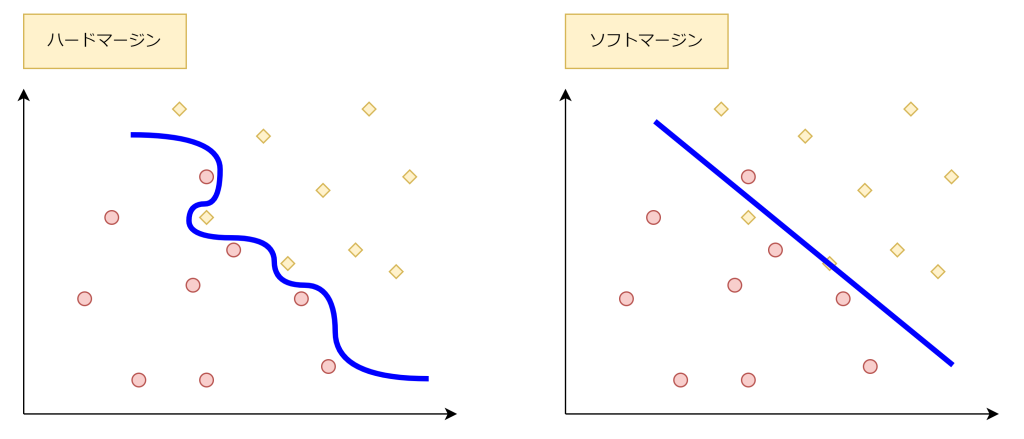
誤分類の最小化 (ソフトマージンとハードマージン)
これまでの図は分かりやすいように、データポイントが綺麗に分離されていました。しかし、現実はそう綺麗に境界線を引くことはできません。境界線を直線ではなく曲線で引くことにより分類することはできます(ハードマージン)。しかし、無理して境界線を引くと過学習を起こしかねませんので、ある程度は誤分類を許容して境界線を引きます(ソフトマージン)。ソフトマージンは過学習を防ぎ、汎化性能を向上させます。
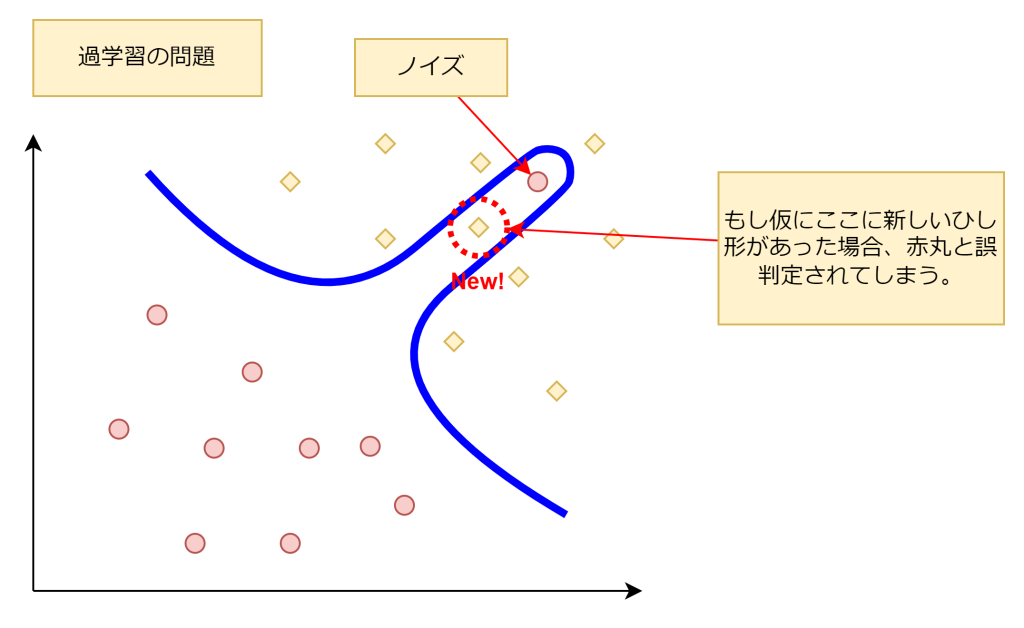
過学習について
過学習について説明します。過学習は、学習しすぎてしまい、機械学習が正しい判断を行えなくなる現象です。大量の学習データの中にはノイズが存在し、そのノイズを学習してしまうことにより、正しく判断が行えなくなるケースがあります。
例えば、以下の図では右上(ひし形のデータが集まっている個所)に、赤丸のノイズが存在します。そのノイズに合わせて境界線を引いた場合、新しいひし形を赤丸と判断してしまいます。この過学習は、SVMだけでなく、他の機械学習でも起こり得る現象です。機械学習では、いかに過学習を起こさせないかが大事になります。
カーネルトリックとカーネル関数
これまではそれとなく直線の境界線を引けました。では、以下の左図はどうでしょうか。ひし形が中央に集まり、赤丸がそれを囲うように点在しています。この場合、あえて次元を増やすことで、この複雑な分類問題を解決することができます。
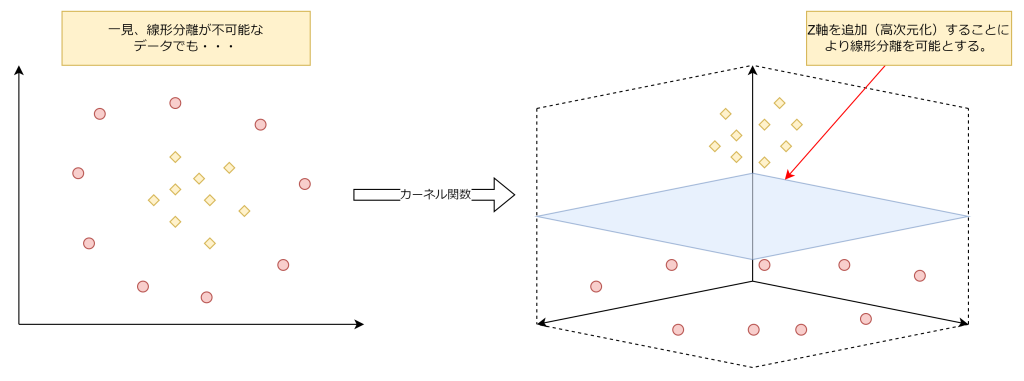
カーネル関数は、実際に次元を追加することなく、データポイント間の類似度を計算して高次元空間にマッピングすることにより、複雑な分類問題を効率的に解決することができます。この手法をカーネルトリックと言います。
おわりに
基本ということで、2次元の平面でお話ししましたが、サポートベクターマシンは多次元説明変数に対しても効率よく分類タスクを行うことができます。また、複雑な分類タスクにも対応し、高精度な予測を行えることから、ディープラーニングが登場するまでは機械学習の中で人気のあるアルゴリズムだったそうです。
ではまた。



















