ランダムフォレストとは何か?
皆さん、こんにちは。LP開発グループのn-ozawanです。
今日(4/23)は、ユネスコが制定した「世界図書・著作権デー」です。「世界本の日」とも呼ばれています。また、日本では「子ども読書の日」として、公共図書館で子ども向けのイベントが開催されているそうです。
本題です。
機械学習のアルゴリズムは数多くあり、ランダムフォレストもそのうちの1つです。ランダムフォレストはシンプルながら、予測の説明が可能なAI(XAI)でもあり、幅広く利用されています。今回はそんなランダムフォレストについて基本を押さえていきたいと思います。
目次
ランダムフォレスト
概要
ランダムフォレストは、機械学習におけるアンサンブル学習手法の一つで、複数の決定木を組み合わせて予測を行います。回帰分析、分類分析のどちらでも利用することができます。
ランダムフォレストは、学習に用いるデータから一部のデータをランダムに取り出して決定木を作成します。それを複数作成して、多数決もしくは平均値を求めることにより予測を行います。ランダムに作成された複数の決定木を組み合わせて使用することから、ランダムフォレストと呼ばれています。
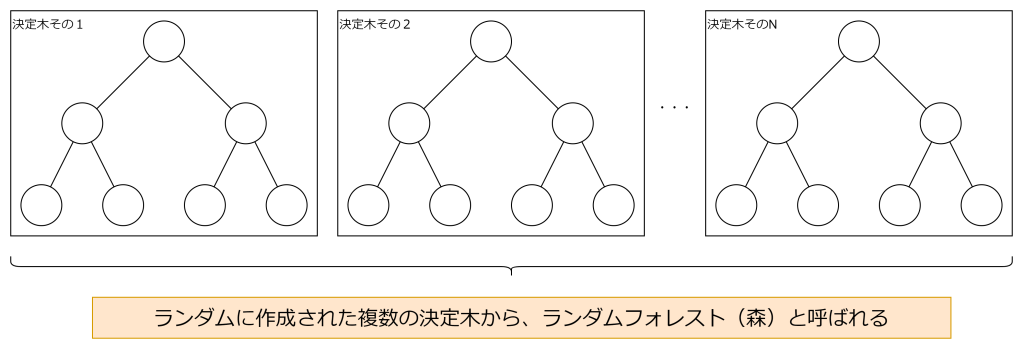
決定木
決定木は、データを条件に基づいて分割し、木構造を形成するアルゴリズムです。各ノードは特徴量に基づく条件を表し、分岐を繰り返すことでデータを分類または予測します。例えば、分類タスクでは、葉ノードがクラスラベルを示し、回帰タスクでは数値を予測します。
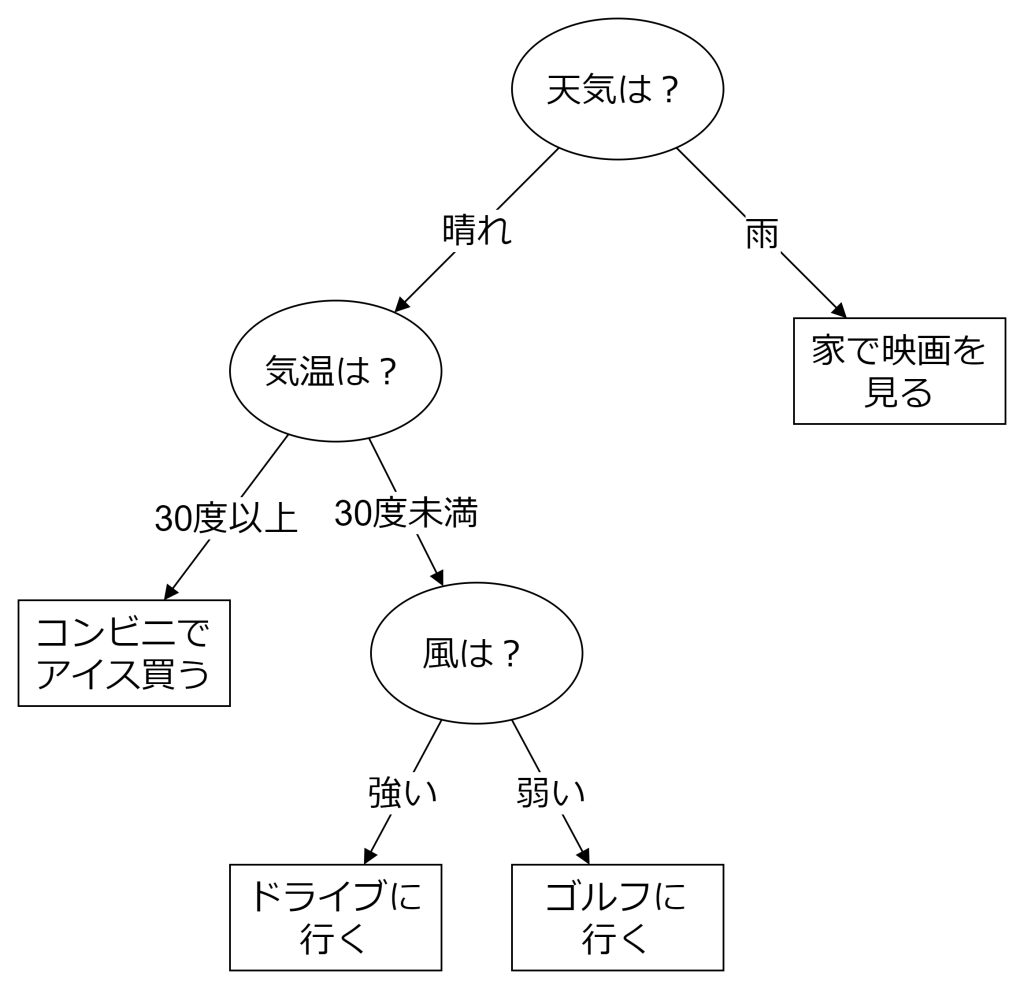
決定木の利点として、直感的に理解しやすく、前処理が少なくて済む点が挙げられます。一方で、過学習しやすいという欠点もあります。
アンサンブル学習(バギング)
アンサンブル学習は、複数のモデルを組み合わせて予測精度を向上させる手法です。良く知られるアンサンブル学習には、バギングとブースティングがあり、ランダムフォレストではバギングが用いられます。
バギングは、学習データからランダムにデータセットを作成し、それぞれのデータセットを用いて個別のモデル(ランダムフォレストであれば決定木)を学習させます。そして、それらの予測結果を統合し、分類タスクでは多数決、回帰タスクでは平均値を取ることで最終的な予測を行います。仮にどれか1つの決定木の精度が悪かったとしても、全体的には集合知の形で高い精度を実現できます。
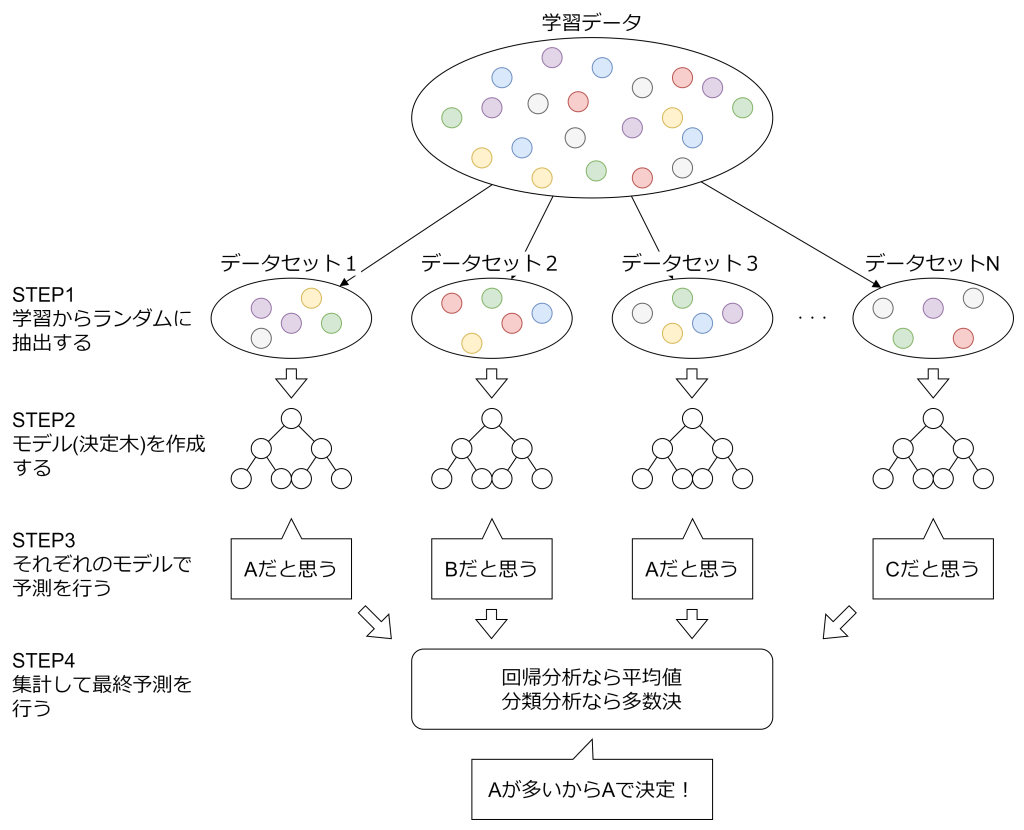
バギングの利点は、個々のモデルが独立しているため、過学習を抑えつつモデル全体の汎化性能を向上させる点になります。一方で、計算コストが高くなりがちであり、特に、大規模なデータセットや多数の決定木を使用する場合、学習や予測に時間がかかることがあります。
おわりに
ランダムフォレストは、学習(決定木を作成)するプロセスを除けば、複雑な数式が出てこないため、理解しやすいですね。また、予測の根拠が説明可能なXAI (Explainable AI) としての特性もあり、安心して利用できます。そういった性質からか、ランダムフォレストは、医療や金融などの分野で広く活用されています。
ではまた。



















