単回帰の線形回帰を実装してみる
皆さん、こんにちは。技術開発グループのn-ozawanです。
キャベツが安くなりましたね!キャベツはそのまま千切りにしてもいいし、炒め物や煮物でも活躍します。この時期であれば春キャベツと新玉ねぎを使ったポトフも美味しいです。
本題です。
前回、線形回帰に関する基本的な知識を整理しました。今回は線形回帰を求める手法を紹介しつつ、実際にコーディングしてみたいと思います。
目次
単回帰分析
最小二乗法
単回帰分析は、1つの説明変数と1つの目的変数の関係を分析する手法であり、X軸とY軸の二次元で表現することができます。よって、単回帰の線形回帰はy = ax + bの一次関数で表すことができます。この式におけるaは傾きであり、bは切片と言います。このaとbを求めることで、x(説明変数)が与えられたときの、y(目的変数)を導くことができるようになります。
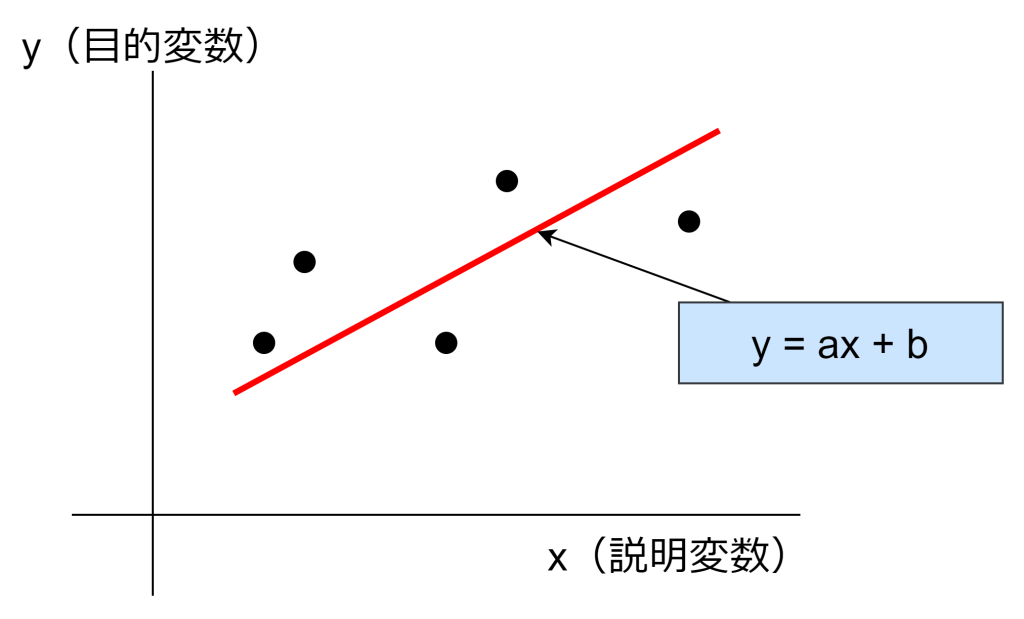
このa(傾き)とb(切片)のことを回帰係数と呼ばれ、多くの場合、最小二乗法により求めます。最小二乗法とは、y(目的変数)と直線の差を二乗して合計した値が最小となるように、最もらしい線を引く手法です。
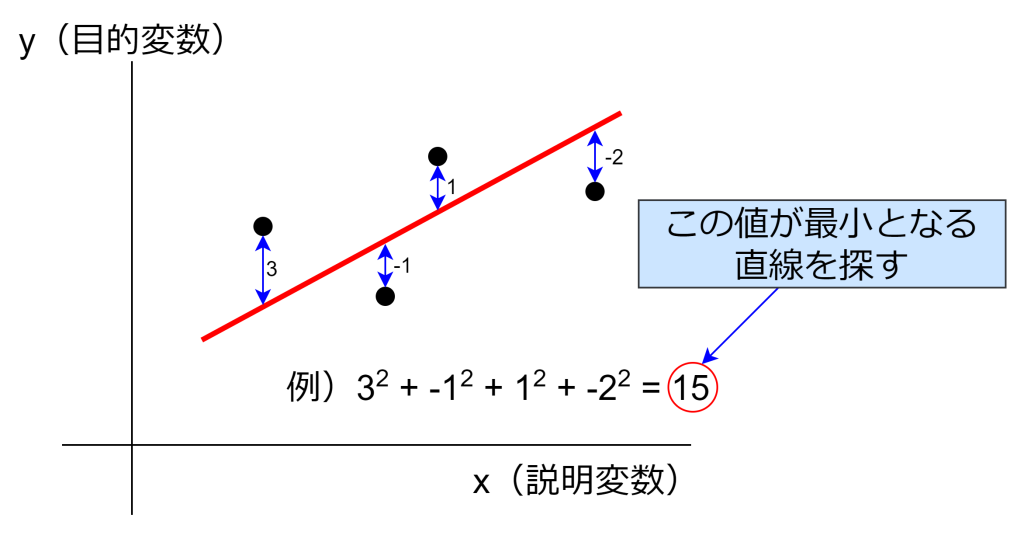
「y(目的変数)と直線の差を二乗して合計した値が最小」となる値を求めるには、偏微分を用いて傾きが0になる値を探します。この偏微分を解くことで以下の式となり、aとbの値を求めることができるようになります。
分散とは?
分散はデータのばらつきを表す指標の一つであり、データが平均値からどれだけ離れているかを示します。具体的には、各データ点と平均値との差を二乗した値の平均を計算することで求められます。分散が大きいほどデータのばらつきが大きく、小さいほどデータが平均値の近くに集中していることを意味します。
例えば、とある5人のクラスでテストが行われ、それぞれ90点、70点、40点、30点、60点というケースを考えます。各点数と平均点との差を二乗した値の平均は456となり、分散は456となります。
なお、この分散の平方根を標準偏差と言います。分散と一緒に覚えておくとよいでしょう。
共分散とは?
共分散は、2つの変数xとyがどのように連動して変化するかを示す指標です。具体的には、xの偏差とyの偏差を掛け合わせた値の平均を計算することで求められます。偏差とは、その値と平均との差です。共分散が正の値であれば、2つの変数は同じ方向に変化する傾向があり、負の値であれば逆方向に変化する傾向があることを意味します。
例えば、とある5人のクラスでテストが行われ、それぞれ国語が90点、70点、40点、30点、60点、数学が70点、80点、60点、20点、40点というケースを考えます。この場合、共分散は328となり、国語の点数と数学の点数で関連性があるとみることができます。
| 名前 | 国語 | 数学 |
|---|---|---|
| Aさん | 90点 | 70点 |
| Bさん | 70点 | 80点 |
| Cさん | 40点 | 60点 |
| Dさん | 30点 | 20点 |
| Eさん | 60点 | 40点 |
計算してみる
話を戻して、実際に計算してみましょう。以下のデータの回帰係数を求めます。
| 名前 | 身長 (x説明変数) | 体重 (y目的変数) |
|---|---|---|
| Aさん | 160cm | 50kg |
| Bさん | 170cm | 68kg |
| Cさん | 180cm | 76kg |
| Dさん | 150cm | 45kg |
| Eさん | 165cm | 53kg |
まずは「xの分散」を求めます。x(説明変数)は身長です。
次に「xとyの共分散」を求めます。y(目的変数)は体重です。
a(傾き)とb(切片)を求めます。
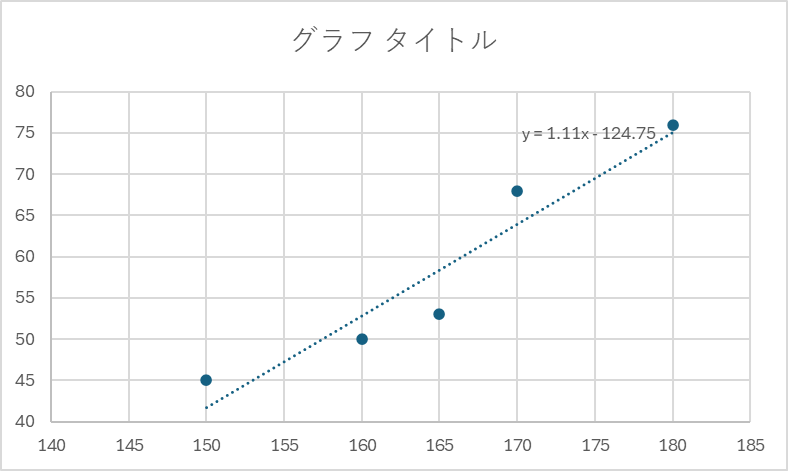
aが1.11、bが-124.75と求められました。Excelで同じデータを使用してグラフを作成し、近似曲線(線形)を表示すると、今回求めたaとbと一致する直線が引かれていることが確認できます。
Pythonで実装してみる
pythonのコードは以下の通りです。分散や共分散などの計算にはnumpyを利用しています。
import numpy as np
# データ
heights = np.array([160, 170, 180, 150, 165]) # 身長
weights = np.array([50, 68, 76, 45, 53]) # 体重
# 平均を計算
mean_height = np.mean(heights)
mean_weight = np.mean(weights)
# 身長の分散を計算
height_variance = np.var(heights)
# 共分散を計算
covariance = np.cov(heights, weights, bias=True)[0][1]
# 傾き a を計算
a = covariance / height_variance
# 切片 b を計算
b = mean_weight - a * mean_height
# 結果を表示
print(f"傾き a: {a}")
print(f"切片 b: {b}")
おわりに
今回は線形回帰のロジックを理解するために、numpyを使ってコーディングしました。実際はScikit-learnなどの機械学習ライブラリがありますので、そちらを使用する方が良いか思います。
ではまた。



















