S3 データレイク を整理する
皆さん、こんにちは。技術開発グループのn-ozawanです。
最近、Google検索するとAIが回答してくれるようになりましたね。
本題です。
2006年に登場したS3はAWSの中心ともいえるサービスです。S3はその可用性や堅牢性を持ち、大規模にデータを保持することが出来ます。保持したデータを分析し可視化することにより、新たなビジネスチャンスを得られることがあります。今回はS3を中心としたデータレイクに何があるのかを整理します。
目次
S3 データレイク
データレイクとは
データレイクとは、構造化されたデータや非構造化されたデータまで、多種多様なデータを一元管理したレポジトリです。AWS S3はデータレイクに適したサービスです。S3に保持された多種多様なデータを分析し可視化することにより、新たな気付きやビジネスチャンスを得られるようになります。
AWSでは、S3に保持されたデータを分析するためのサービスとして以下があります。
- AWS Glue
- Amazon Athena
- AWS Lake Formation
- Amazon EMR
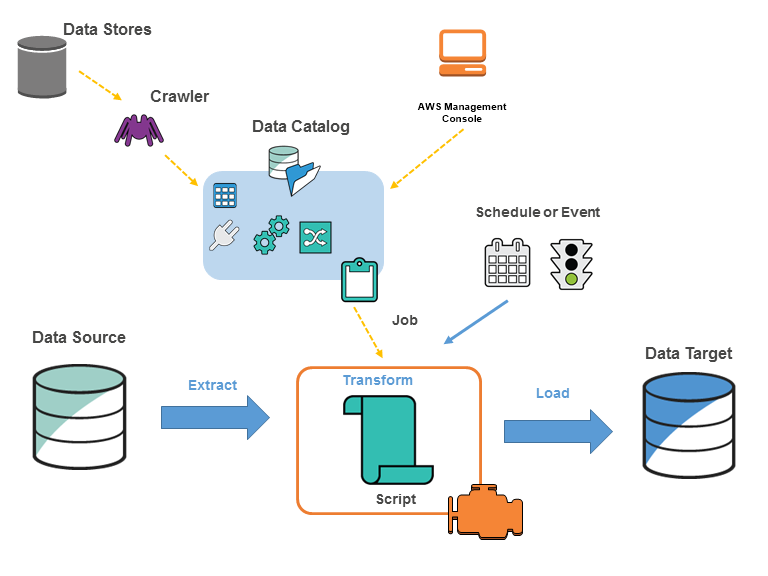
AWS Glue
AWS GlueはETLサービスです。ETLとは抽出(Extract)、変換(Transform)、格納(Load)の頭文字を取ったデータフローです。抽出可能なデータソースにはS3以外にもRDSやDynamoDBなど、構造化データから非構造化データまで、幅広く対応しています。
処理の流れとしては、まず、クローラーによりデータソースからメタデータを抽出して、データカタログとして定義します。データカタログはメタデータを扱うデータストアです。その後、Glueジョブにより変換処理を行い、別のデータソースとして出力します。
これにより、S3に保存された多種多様な形式のデータを、Apache Parquet形式などの分析しやすいデータへ効率よく変換することが出来るようになります。
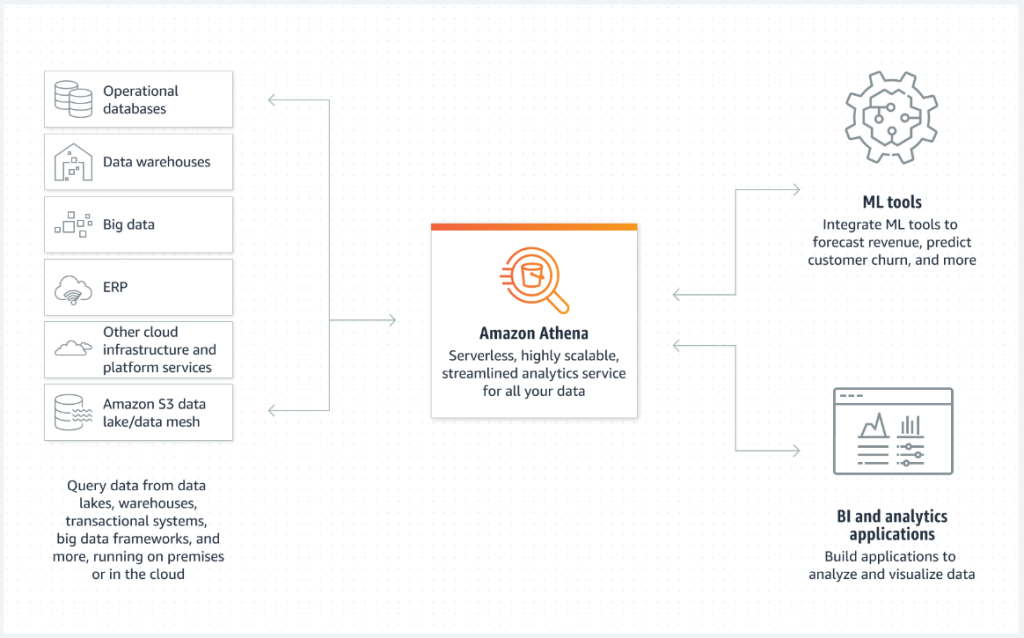
Amazon Athena
Amazon Athenaは、S3内のデータをSQLを使用して分析することが出来るサービスです。S3に格納したCSV、JSON、ParquetなどのデータをSQLで分析することが出来ます。Amazon Athenaでは、Glueデータカタログに対してクエリを実行します。なので、Glueと併用して使われることが多いようです。
また、Athenaでクエリした結果をQuickSightやPower BIなどにより可視化/分析することも可能です。
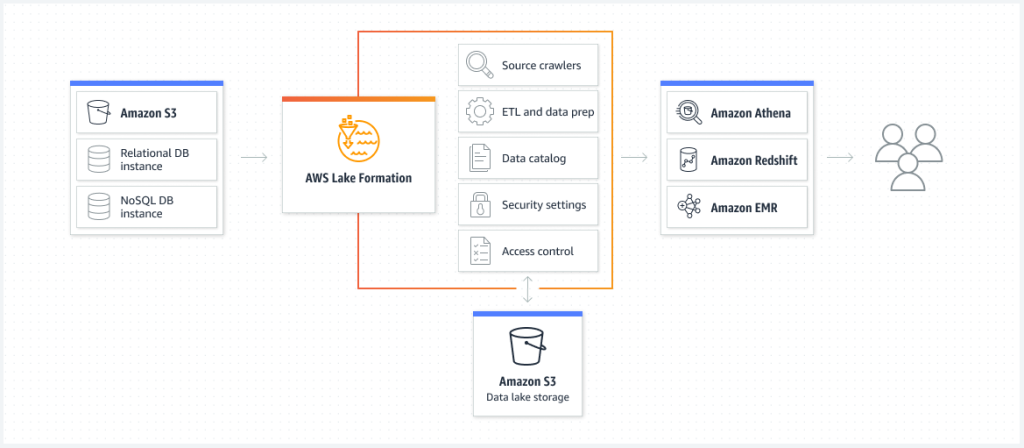
AWS Lake Formation
AWS Lake Formationは、データレイクを管理、運用するためのサービスで、データレイクの素早い構築ときめ細かいアクセス制御を提供します。特別新しい機能を提供している訳ではなく、AWS GlueやIAMなどのアクセス制御をお手軽に構築してくれるサービスになります。
Amazon EMR
Amazon EMRは、Apache HadoopやApache Sparkなどのビックデータワークフローを利用して、データの分析や処理を行うサービスです。EMRではクラスターと呼ばれる複数のノードにて分散処理を行うことにより、大規模データの分析を高速に行うことが出来ます。
Amazon Kinesisなどのストリーミングサービスと組み合わせることにより、ペタ単位の大規模データをリアルタイムで分析することが可能となります。
おわりに
データを可視化することは、現状を明確にし、正しく分析することで次の指標にもなります。ビジネスも含めて、現代の環境変化は著しく、常にその変化についていく必要があります。1度構築したからと言って安心していると、次の年では置いて行かれるかもしれません。その為にも、日ごろからデータ分析が行える環境を構築し、世の中の変化に柔軟に対応できるようにしたいものです。
ではまた。



















